rayonとtokioの使い分け
Rustで少し重い処理を書き始めると、rayonとtokioはどちらも選択肢に上がる。呼び出し規約はどちらも「並列っぽい」ので、その場で正解を選ぼうとすると判断がつかない。
つかないのは、両者が同じ問題を別の方法で解いているように見えるからだ。実際にはそうではない。rayonは要素列をワーカーに分配してCPU時間を潰すためのライブラリ、tokioは待ちを含む多数のタスクを少数のOSスレッド上に多重化するランタイム。tokioでCPU仕事を回すこと自体は可能だが、単一タスクが.awaitを挟まないと同じワーカーの他タスクが動けなくなる。目的も苦手も違うので、答えは速度比較ではなく仕事の性質から出る。
rayonとtokioは違う問題を解いている
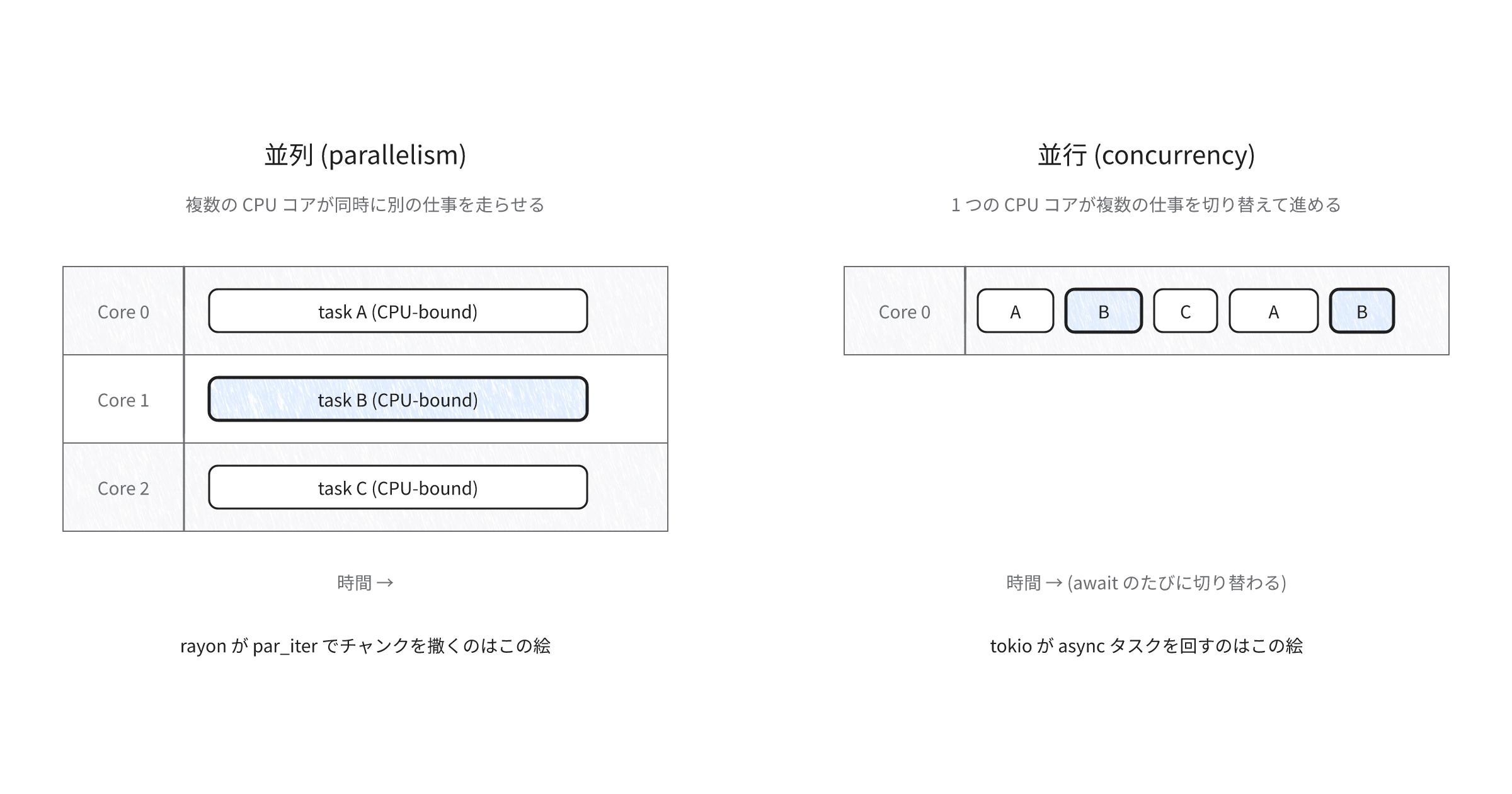
日本語で混同しやすい2語を先に切り離す。並列(parallelism、複数の仕事を同時に走らせる)と並行(concurrency、複数の仕事を同じ時間帯にまたがって進める)は違う。並列は複数のCPUコアに仕事を割り振る話で、並行はコアが1本しかなくても、待ちのある仕事を交互に進めれば成立する。
この区別で見ると、両者の分担はきれいに分かれる。
rayonはデータ並列(parallelism)を担うライブラリ。固定数のスレッドプールで work-stealing(余ったスレッドが他のスレッドの仕事を横取りする方式)を回し、要素列をチャンクに分けて分配する。CPU律速な計算(数値変換や集計、画像処理など)を並列にすり潰す用途に向く。tokioはタスク並行(concurrency)を担う async ランタイム。少数のOSスレッド(ワーカー)の上に多数の async タスクを載せ、.awaitに到達したタスクを一時停止して別のタスクへ切り替える方式で進める。本領は I/O 律速な待ち(HTTP、ファイル、DB、外部プロセスなど)にある。
同じ「並列に処理する」に見えても、rayonは要素ごとの計算を並列に走らせ、tokioは待ちを含むタスクを重ねて進める。両者は競合するライブラリではなく、目的が違うので置き換えられない。
tokio のワーカースレッドは 1 本ずつしかタスクを進められない。切り替えの合図はタスク側の .await だけだ。.await を通らないコード(重い for ループなど)を async タスクに書くと、そのタスクが終わるまでワーカーが握られっぱなしになり、同じワーカーで順番待ちしていた他タスクは動けない。CPU 仕事も動かせるが、この制約はついて回る。
rayonの基本
rayonの入り口は、標準のIteratorをParallelIteratorに差し替えるところにある。依存を1行加えてuse rayon::prelude::*を書けば、既存のiter呼び出しをpar_iterに置き換えるだけで並列版が使える。
# Cargo.toml
[dependencies]
rayon = "1.11"
use rayon::prelude::*;
1. iterをpar_iterに置き換える
もっとも単純な例は、大きなVec<u64>の総和だ。
// 1000 万個の u64 を並べたベクタを作る
let xs: Vec<u64> = (0..10_000_000).collect();
// 逐次版: 標準の iter().sum() で先頭から順に足す
let t0 = Instant::now();
let seq: u64 = xs.iter().sum();
let seq_ms = t0.elapsed().as_millis();
// 並列版: iter を par_iter に差し替えるだけ。rayon が要素列を
// チャンクに切ってワーカースレッドに配り、部分和を最後にまとめる
let t1 = Instant::now();
let par: u64 = xs.par_iter().sum();
let par_ms = t1.elapsed().as_millis();
// 逐次版と並列版で結果が一致することを確認
assert_eq!(seq, par);
println!("sum: iter={seq} ({seq_ms}ms) par_iter={par} ({par_ms}ms)");
22ワーカー環境の出力。
num_cpus (rayon の既定 worker 数): 22
sum: iter=49999995000000 (1ms) par_iter=49999995000000 (1ms)
逐次版がすでに1msしかかかっていない。1要素あたりの仕事が「64ビット加算1回」しかないので、rayonが分割・スケジュール・集約する分の間接費(オーバーヘッド)と、逐次側の実測が同じ丸め幅(1ms未満)に収まってしまう。並列化してwall-clockが短くなるのは、要素ごとに十分なCPU仕事があるときだけだ。
2. map+collectで並列化する(順序は保存される)
1要素あたりの仕事量を増やしてみる。2000回のwrappingオペレーションのループを1要素ごとに走らせるsquare_wave関数を用意し、100万要素にかける。
// n 一つに対して 2000 回の wrapping 演算を回す純関数。
// black_box は「この値は使う」と LLVM に伝えて最適化除去を防ぐ壁で、
// ベンチマークで意味のある実測を取りたいときに置く。
fn square_wave(n: u64) -> u64 {
let mut acc = std::hint::black_box(0u64);
for i in 0..2_000 {
acc = acc.wrapping_add(std::hint::black_box(n).wrapping_mul(i).wrapping_add(i));
}
acc
}
// 100 万要素の入力
let ys: Vec<u64> = (0..1_000_000).collect();
// 逐次版: iter().map() で 1 要素ずつ square_wave を通し、Vec に集める
let t0 = Instant::now();
let seq: Vec<u64> = ys.iter().map(|&n| square_wave(n)).collect();
let seq_ms = t0.elapsed().as_millis();
// 並列版: par_iter().map() に置換。rayon が入力を分割してワーカーに配り、
// 各ワーカーが部分ベクタを作って、collect が入力順に結合する
let t1 = Instant::now();
let par: Vec<u64> = ys.par_iter().map(|&n| square_wave(n)).collect();
let par_ms = t1.elapsed().as_millis();
// 並列版でも要素順は保存されるので、逐次版と Vec が一致する
assert_eq!(seq, par);
std::hint::black_boxは、LLVMが定数畳み込みで計算を丸ごと除去するのを防ぐための壁として置く。ベンチマークで意味のある結果を取りたいときに使うテクニックだ。同じ環境で1M要素を回した結果。
map+collect: iter=(1189ms) par_iter=(93ms) checksum=0xddef0dd0bd86b00
22ワーカーで走らせて約13倍まで縮む。順序も保存されるので、逐次版と並列版で assert_eq が通る(rayon が分割したスライスを collect が最後に結合する)。
3. mandelbrotで「意味のあるCPU仕事」を回す
もう少し実用に近い例として、mandelbrot集合の可視化に使う発散判定を1ピクセルずつ計算する。1ピクセルあたり最大200回のループが回るので、そこそこの重さになる。
// 1 ピクセルの発散判定。最大 max_iter 回のループで z_{n+1} = z_n^2 + c を回し、
// 発散したところで抜ける。返り値は発散までにかかった反復数。
fn mandelbrot_pixel(px: usize, py: usize, w: usize, h: usize, max_iter: u32) -> u32 {
let cx = (px as f64 / w as f64) * 3.5 - 2.5;
let cy = (py as f64 / h as f64) * 2.0 - 1.0;
let mut x = 0.0f64;
let mut y = 0.0f64;
let mut i = 0u32;
while x * x + y * y <= 4.0 && i < max_iter {
let xn = x * x - y * y + cx;
let yn = 2.0 * x * y + cy;
x = xn;
y = yn;
i += 1;
}
i
}
// 800 x 600 の画像を作り、1 ピクセルあたり最大 200 回のループを回す
let (width, height, max_iter) = (800usize, 600usize, 200u32);
// 逐次版: 標準の flat_map で行(py) を外、列(px) を内として全ピクセルを 1 本の
// イテレータに畳み、collect で Vec に詰める
let t0 = Instant::now();
let seq: Vec<u32> = (0..height)
.flat_map(|py| (0..width).map(move |px| mandelbrot_pixel(px, py, width, height, max_iter)))
.collect();
let seq_ms = t0.elapsed().as_millis();
// 並列版: 外側の range を into_par_iter で並列化し、内側は flat_map_iter に置く
// (「外は並列、中は逐次イテレータ」の組み合わせ)。行単位で分割して各ワーカーへ配る
let t1 = Instant::now();
let par: Vec<u32> = (0..height)
.into_par_iter()
.flat_map_iter(|py| (0..width).map(move |px| mandelbrot_pixel(px, py, width, height, max_iter)))
.collect();
let par_ms = t1.elapsed().as_millis();
// 画像 (Vec<u32>) が逐次版と並列版で完全に一致することを確認
assert_eq!(seq, par);
into_par_iterとflat_map_iterは、外側の範囲を並列に分割し、内側は逐次のイテレータのまま流す組み合わせだ。この形は「行単位で並列」の書き方として使いやすい。
mandelbrot 800x600: iter=(70ms) par_iter=(6ms) sum=23077341
22ワーカーで約12倍まで縮む。数字は機種と実装最適化で動くが、順序保存と結果同一性はいずれの場合も成り立つ。
tokioの基本
tokioの入り口はrayonと違う。並列イテレータではなく、待ちを含む関数をasync fnで書き、.awaitで待つ、というスタイルになる。Cargo.tomlにfeaturesを指定して依存を入れる。
# Cargo.toml
[dependencies]
tokio = { version = "1.48", features = ["rt", "rt-multi-thread", "macros", "time", "sync"] }
rtは基本ランタイム、rt-multi-threadは複数スレッド版のスケジューラ、macrosは#[tokio::main]と#[tokio::test]、timeはsleepやtimeout、syncはMutexやSemaphore。使うぶんだけfeatureで有効化すれば、ビルド時間とバイナリサイズが軽く済む。
32 個の擬似 I/O(1 回 100ms の sleep)を、逐次から並列度制限まで 4 段階で試す。
まず逐次で書く
use std::time::{Duration, Instant};
use tokio::time::sleep;
// 擬似 I/O。実際の HTTP 呼び出しや DB クエリを sleep で置き換えている。
// async fn なので、.await のたびにランタイムへ処理を返せる
async fn fetch_one(i: usize) -> usize {
sleep(Duration::from_millis(100)).await;
i * 2
}
// #[tokio::main] は main を tokio ランタイムで包むマクロ。
// これで async fn main() が書けるようになる
#[tokio::main]
async fn main() {
let t0 = Instant::now();
let mut seq_results = Vec::with_capacity(32);
// for + .await で 1 個ずつ待つ。並行化していないので直列に 100ms が積み上がる
for i in 0..32 {
seq_results.push(fetch_one(i).await);
}
let seq_ms = t0.elapsed().as_millis();
println!("sequential: {} results in {seq_ms}ms", seq_results.len());
}
fetch_oneはasync fnで書き、.awaitで完了を待つ。sleepが「他タスクに譲るポイント」だが、この段では譲る先の他タスクが無いので、ただの100ms待ち×32 ≈ 3.3秒として観測される。
sequential: 32 results in 3333ms
tokio::spawn で発火する
tokio::spawnは、asyncブロックを別タスクとしてキューに投げ、JoinHandleを返す。全部投げてから順に.awaitで結果を拾えば、待ち時間が重なる。
use tokio::sync::Semaphore;
use tokio::task::JoinSet;
use tokio::time::sleep;
let t1 = Instant::now();
// 32 個の fetch_one() をまとめて spawn し、それぞれの JoinHandle をベクタに集める。
// この時点でタスクはランタイムにキューされ、ワーカーに拾われ次第走り始める
let handles: Vec<_> = (0..32).map(|i| tokio::spawn(fetch_one(i))).collect();
let mut spawn_results = Vec::with_capacity(32);
// 各 JoinHandle を .await で回収する。すでに走り終わっていれば即返る
for h in handles {
spawn_results.push(h.await.expect("task panic"));
}
let spawn_ms = t1.elapsed().as_millis();
全32個が並行してsleepするので、合計は100ms前後に縮む。
tokio::spawn: 32 results in 104ms
JoinSet でまとめて収集する
JoinSetは「多数のタスクを投げて、終わった順に結果を回収する」ためのコンテナだ。Vec<JoinHandle>とfor h in handlesの2行を1つの型に畳める。
let t2 = Instant::now();
// タスクをためる箱を用意
let mut set = JoinSet::new();
// 32 個の fetch_one() を set.spawn で投げ込む。JoinHandle は set が持ってくれる
for i in 0..32 {
set.spawn(fetch_one(i));
}
let mut joinset_results = Vec::with_capacity(32);
// 終わったタスクから順に join_next().await で取り出す。全部取り終わったら None
while let Some(joined) = set.join_next().await {
joinset_results.push(joined.expect("task panic"));
}
let joinset_ms = t2.elapsed().as_millis();
wall-clockはtokio::spawn版とほぼ同じ。
JoinSet: 32 results in 101ms
Semaphore で並列度を絞る
外部APIを叩くようなI/Oは、レート制限や上流のスループットの都合で「同時に何本まで」に絞りたい。Semaphore(許可(permit)を貸し出すカウンタ)を1つ用意し、タスクの先頭で1本借り、終わったら返せば、常時同時数がキャップされる。
use std::sync::Arc;
let t3 = Instant::now();
// permit を最大 4 枚まで貸し出す Semaphore を作り、Arc で複数タスクから共有する
let sem = Arc::new(Semaphore::new(4));
let mut set = JoinSet::new();
for i in 0..32 {
// タスクごとに Arc をクローンして move で持ち込む
let sem = Arc::clone(&sem);
set.spawn(async move {
// permit を 1 枚借りる。上限に達していれば await で待たされる
let _permit = sem.acquire_owned().await.expect("semaphore closed");
// 本体の I/O。抜けると _permit が drop され、permit が Semaphore に返る
fetch_one(i).await
});
}
let mut limited_results = Vec::with_capacity(32);
while let Some(joined) = set.join_next().await {
limited_results.push(joined.expect("task panic"));
}
let limited_ms = t3.elapsed().as_millis();
_permitは_から始まるので警告は出ないが、束縛はしている。ブロックの終わりでdropされてSemaphoreに返却される。32本 / 同時4本 = 8バッチ × 100ms = 約800ms。
JoinSet+Semaphore(4): 32 results in 836ms
実行モデルの違い
rayonのmandelbrotは10倍以上速くなり、tokioのJoinSetは3.3秒を0.1秒まで縮めた。どちらも「並列」に見えるが、内部で走らせているものはまったく違う。
rayon の内部モデル
rayonは、初回に並列 API が呼ばれたタイミングでCPUコア数と同じくらいのワーカースレッドを持つグローバル・プール(ThreadPool)を1つ初期化する(ThreadPoolBuilder::build_global で明示することもできる)。par_iterは要素列を「チャンク(chunk、まとまり)」に分けてこのプールに投げる。あるスレッドが自分のキューを空にすると、他のスレッドのキューの尻から仕事を横取り(steal)する。これが work-stealing で、粒度の偏りに強い。
x0, x1, x2, ..."] --> split["ランタイムがチャンクに分割"] split --> W0 split --> W1 split --> W2 split --> W3 subgraph pool["ワーカープール(CPU コア数と同数、常駐)"] W0["Worker 0
ローカルキュー: 3 個"] W1["Worker 1
ローカルキュー: 2 個"] W2["Worker 2
ローカルキュー: 空"] W3["Worker 3
ローカルキュー: 4 個"] end W2 -. work-stealing
末尾から横取り .-> W3
ワーカースレッドは常時プールに居座る。仕事が来なければ寝ているだけで、来たら計算する。CPUを回す前提で作られている。
tokio の内部モデル
tokioは、少数のOSスレッド(既定でrt-multi-threadならnum_cpusぶん)と、無数のasyncタスクを組み合わせる。.awaitにぶつかると、タスクは自分の状態を保存して譲り、OSスレッドは次に走らせられる別のタスクを取りに行く。
I/O完了通知の受け口として、OSのイベントAPI(Linuxならepoll、macOSならkqueue、Windowsならcompletion port)をmio経由で使う。これがreactor。tokio::time::sleepはタイマーを登録し、期限が来たらreactorがタスクを起こす仕組み。ネットワーク待ちも同じで、ソケットが読める状態になったらreactorが該当タスクを起こす。
タスク1本の一生を状態で追うと、Ready(spawn 直後)→Running(ワーカー上で実行中)→Waiting(.awaitで譲って I/O 完了待ち)→Ready(reactor が起こしなおす)というループになる。
tokio は待ちを回す前提で作られている。
「速度比較」は成り立たない
「rayon vs tokio の速度比較」が的外れになる理由もここから出る。rayonの得意技はCPU律速の要素列を分割してぶん回すこと。tokioの得意技はI/O待ちを重ねること。仕事がCPU律速ならrayonが勝ち、I/O律速ならtokioが勝つ。速度を並べても、答えは目の前の仕事の性質で決まる。
使い分けを間違えたとき
2 通りを試す。rayon の中で同期 sleep した場合と、tokio の中で .await なしに CPU を回した場合を順に測る。
(a) rayonの中で同期sleepを混ぜる
外部APIを叩くような「待ちのある仕事」を、うっかりpar_iterに混ぜてみる。rayonのワーカースレッドはCPUを回す前提で数が固定なので、sleepで寝ているワーカーは他の仕事を取れない。
use rayon::prelude::*;
fn demo_rayon_blocking() {
// rayon の worker 数を 4 に固定した専用プールを作る。
// 既定のグローバルプールと分けたいときは ThreadPoolBuilder + install を使う
let pool = rayon::ThreadPoolBuilder::new()
.num_threads(4)
.build()
.expect("build rayon pool");
// 16 個の要素を並列に処理させる
let items: Vec<usize> = (0..16).collect();
// install 内の par_iter だけがこのプールに落ちる
let elapsed_ms = pool.install(|| {
let start = Instant::now();
let _out: Vec<usize> = items
.par_iter()
.map(|&i| {
// ここで同期 sleep を挟む = ワーカースレッドが 100ms 眠り続ける。
// 眠っている間 rayon はこの worker で別の仕事を進められない
std::thread::sleep(Duration::from_millis(100));
i
})
.collect();
start.elapsed().as_millis()
});
println!("(a) rayon + std::thread::sleep, 4 workers x 16 items: {elapsed_ms}ms");
}
4ワーカーに16件、各100ms待つと、16 / 4 = 4バッチ × 100ms で400msかかる。
(a) rayon + std::thread::sleep, 4 workers x 16 items: 418ms
(同じ仕事を tokio async でやれば ~100ms)
同じ待ちをtokioのJoinSetで32本並行すれば約100msに収まっていたのに、rayonに投げると4倍遅い。ワーカーはCPUを回すためのもので、ぼーっと待たせるための枠ではない。
(b) async タスクの中で .await を挟まずCPUをぶん回す
逆に、async fnの中で.awaitを挟まずに重いループを回すと、そのタスクが載っているワーカースレッドは丸ごと塞がる。rt-multi-threadなら他のワーカーは動き続けるが、ワーカーが1本しかないcurrent_threadランタイムだと症状がはっきり出るので、そちらで観察する。
use tokio::time::sleep;
fn demo_tokio_cpu() {
// ワーカー 1 本しかない current_thread ランタイムを作る。
// これで「CPU で塞がると誰も動けない」という症状が観察しやすくなる
let rt = tokio::runtime::Builder::new_current_thread()
.enable_all()
.build()
.expect("build tokio runtime");
rt.block_on(async {
let start = Instant::now();
// heartbeat タスク: 50ms 毎に「経過時間」を記録し続ける軽量な監視役。
// 譲り合いが働いていれば ticks は等間隔に並ぶはず
let hb = tokio::spawn(async move {
let mut ticks = Vec::with_capacity(20);
for _ in 0..20 {
sleep(Duration::from_millis(50)).await;
ticks.push(start.elapsed().as_millis());
}
ticks
});
// heartbeat を 150ms ほど回してから CPU 部に入る
sleep(Duration::from_millis(150)).await;
// ここから約 400ms、.await を一切挟まずに CPU を回し続ける。
// 同じワーカー上の他タスク (= hb) はこの間まったく進めない
let cpu_start = Instant::now();
let mut acc = 0u64;
let mut i = 0u64;
while cpu_start.elapsed() < Duration::from_millis(400) {
acc = acc.wrapping_add(i);
i = i.wrapping_add(1);
}
// 最適化で消えないよう black_box に通す
std::hint::black_box(acc);
// heartbeat を回収し、tick 間隔の最大値を出す。
// CPU ループの前後で大きく空くと、そこが「他タスクが凍っていた期間」になる
let ticks = hb.await.expect("hb join");
let cpu_ms = cpu_start.elapsed().as_millis();
let max_gap = ticks.windows(2).map(|w| w[1] - w[0]).max().unwrap_or(0);
println!(
"(b) tokio current_thread + CPU {}ms: heartbeat max gap = {}ms",
cpu_ms, max_gap
);
println!(" heartbeat ticks (ms since start): {:?}", ticks);
});
}
hbは50msごとに「今何ms経ったか」を記録する軽量タスクだ。ふつうなら[50, 100, 150, 200, ...]と等間隔に並ぶ。ところが同じランタイムの上で400msぶんのCPUループを回すと、hbはその間動けない。
(b) tokio current_thread + CPU 400ms: heartbeat max gap = 440ms
heartbeat ticks (ms since start): [56, 112, 552, 607, 660, 712, 764, 816, 869, 923, 976, 1028, 1080, 1133, 1188, 1244, 1297, 1348, 1404, 1459]
max gapが440ms。3個目のtickが112msから552msへ飛んでいる。CPUを回している間、.awaitを通らないので、tokioはhbにスレッドを回せない。
これはrt-multi-threadランタイムでも構図は同じだ。CPU をぶん回すタスクを載せるほどワーカースレッドが順に埋まり、num_cpusぶんのタスクがCPUを握れば、待ちのタスクを進める余地は無くなる。tokioの.awaitベースの譲り合いは、.awaitを通らないコードでは働かない。長いCPUループを async タスクに直書きするなら、tokio::task::yield_nowで明示的に譲るか、spawn_blockingや rayon 側へ逃がして書く。
CPU と I/O が混ざる処理は組み合わせる
実運用の多くの処理は、CPUだけ・I/Oだけでは済まない。ファイルを読み込み、パースして、集計し、外部APIに送る。ネットワークで受け取ったJSONを画像に変換する。データベースから取り出した数百万行を集約する。こういう処理は、CPU側は rayon に、待ち側は tokio に振り分けて書く。
道具立てはtokio::task::spawn_blocking。tokioのランタイムの外側にある「blockingプール」(同期処理向けの別スレッドプール)にクロージャを投げて、返り値を.awaitで受け取る。CPUを回すあいだ、tokioのreactorが使うスレッドを塞がずに済む。そのblockingスレッドの中で rayon を呼び出せば、CPU側も並列化できる。
3段の入れ子として描くとこうなる。
(擬似 HTTP 等)"] io1 --> sb1 t2 --> sb2 tn --> sb3 subgraph bp["2. spawn_blocking = blocking プール"] sb1["blocking worker"] sb2["blocking worker"] sb3["blocking worker"] end sb1 --> rayon sb2 --> rayon sb3 --> rayon subgraph rayon["3. rayon par_iter で要素並列"] r["file.par_iter().map(...).sum()"] end
use std::sync::Arc;
use rayon::prelude::*;
use tokio::sync::Semaphore;
use tokio::task::JoinSet;
use tokio::time::sleep;
#[tokio::main]
async fn main() {
// 8 個の「ファイル」を用意。各ファイルは 10 万個の u64。
// Arc に包むのは spawn_blocking の move キャプチャに渡すため
let files: Vec<Arc<Vec<u64>>> = (0..8)
.map(|f| Arc::new((0..100_000).map(|i| (f * 100_000 + i) as u64).collect()))
.collect();
// I/O は同時 4 本まで。上流 API のレート制限をイメージ
let sem = Arc::new(Semaphore::new(4));
let mut set = JoinSet::new();
for (idx, file) in files.iter().cloned().enumerate() {
let sem = Arc::clone(&sem);
set.spawn(async move {
// permit を 1 枚借りて、この async ブロックの間だけ抱え込む
let _permit = sem.acquire_owned().await.expect("semaphore closed");
// 1 段目 (tokio 外皮): I/O 待ちは async のまま。sleep で他タスクに譲れる
sleep(Duration::from_millis(50)).await;
// 2 段目 (spawn_blocking): CPU 部を blocking プールへ移す。
// これで reactor 用のワーカースレッドを塞がずに済む
let sum: u64 = tokio::task::spawn_blocking(move || {
// 3 段目 (rayon): blocking プールの 1 スレッドの中で、
// ファイル内の要素列を par_iter で並列に畳み込む
file.par_iter().map(|&n| aggregate(n)).sum::<u64>()
})
.await
.expect("spawn_blocking join");
(idx, sum)
});
}
// JoinSet から (index, 集計値) を回収
let mut results = Vec::new();
while let Some(joined) = set.join_next().await {
results.push(joined.expect("task panic"));
}
}
// CPU 側の適度に重い純関数
fn aggregate(n: u64) -> u64 {
let mut acc = 0u64;
for k in 0..20 {
acc = acc.wrapping_add(n.wrapping_mul(k).wrapping_add(k * k));
}
acc
}
tokio がファイル単位をさばき、spawn_blocking が CPU 部を blocking プールへ逃がし、その中で rayon が要素列を並列化する。
まとめ
判断軸は速度ではなく、目の前の仕事が「待つ」か「計算する」かだ。
| 目の前の仕事 | 選ぶ道具 | 書き方の入り口 |
|---|---|---|
| CPU律速な要素列の変換や集計 | rayon |
use rayon::prelude::* してiterをpar_iterに置換 |
| I/O律速な待ち(HTTP、DB、ファイル、外部プロセス) | tokio |
#[tokio::main] とasync fn、JoinSetと必要ならSemaphore |
| CPUとI/Oが混ざる処理 | 両方組み合わせる | tokioを外皮に、spawn_blockingでCPU部を逃がし、その中でrayon |
具体的に避けたいのは次のあたり。
par_iterの中で同期sleepやブロッキングI/Oを走らせない(ワーカーが塞がる)asyncタスクの中で.awaitを挟まずに長いCPUループを走らせない(spawn_blockingかyield_nowで譲る)- 「並列そう」で選ばないで、「これは待つ仕事か、計算する仕事か」で選ぶ
役割を分けて考えれば、混ざった処理も層で組める。