RustでMarkdownをパースする — parserの選び方
RustでMarkdownをパースする — parserの選び方
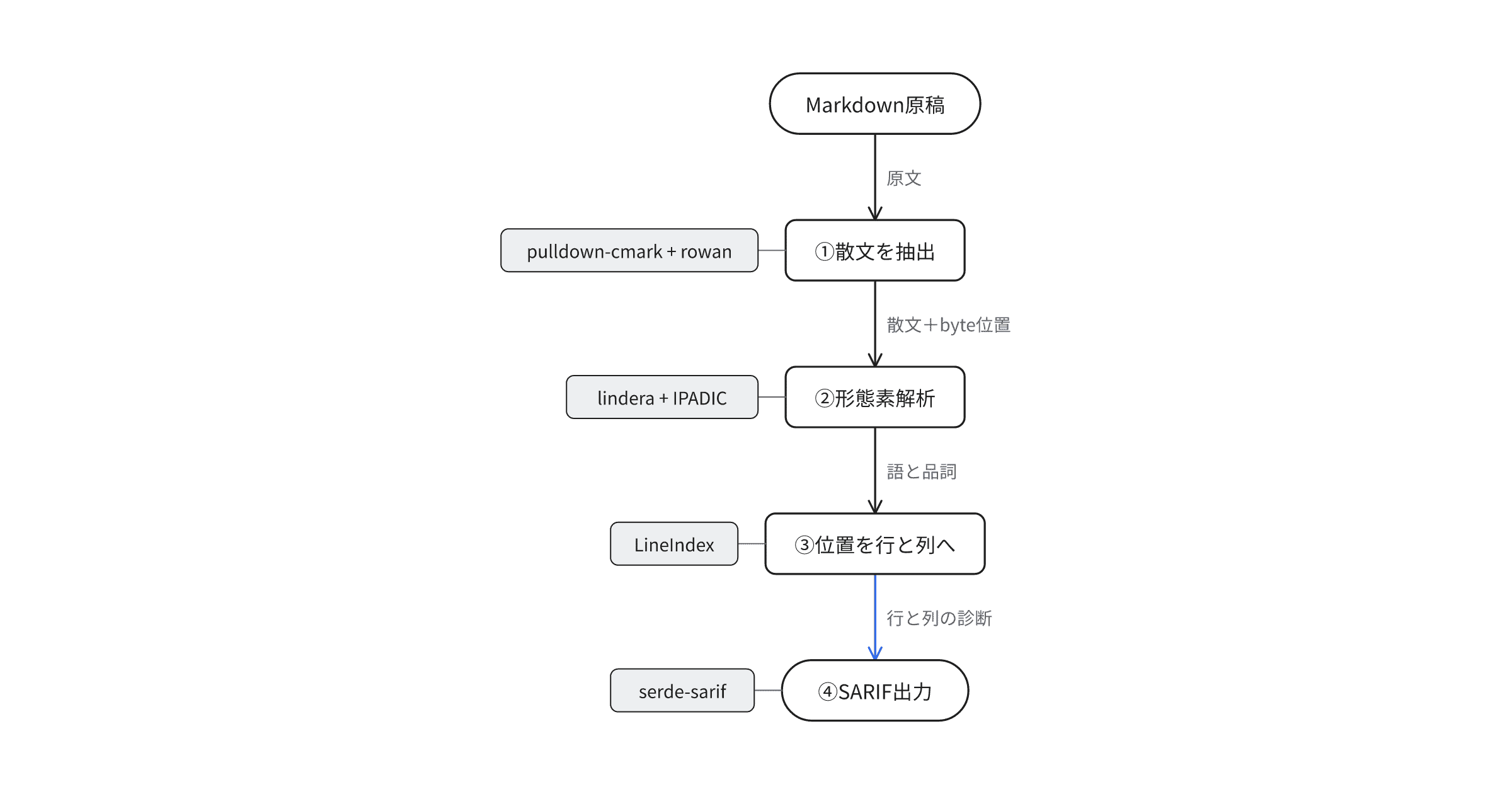
Markdown原稿をlinterや抽出ツールで扱うとき、最初に決めるのはparserライブラリだ。linterを組む段階で「どのcrateをparse層に置くか」で迷った経験はないだろうか。同じ# 見出し一行でも、返ってくるAPIの形と位置情報が違えば、指摘位置の表現(byte / 行・列)や走査方式が変わる。
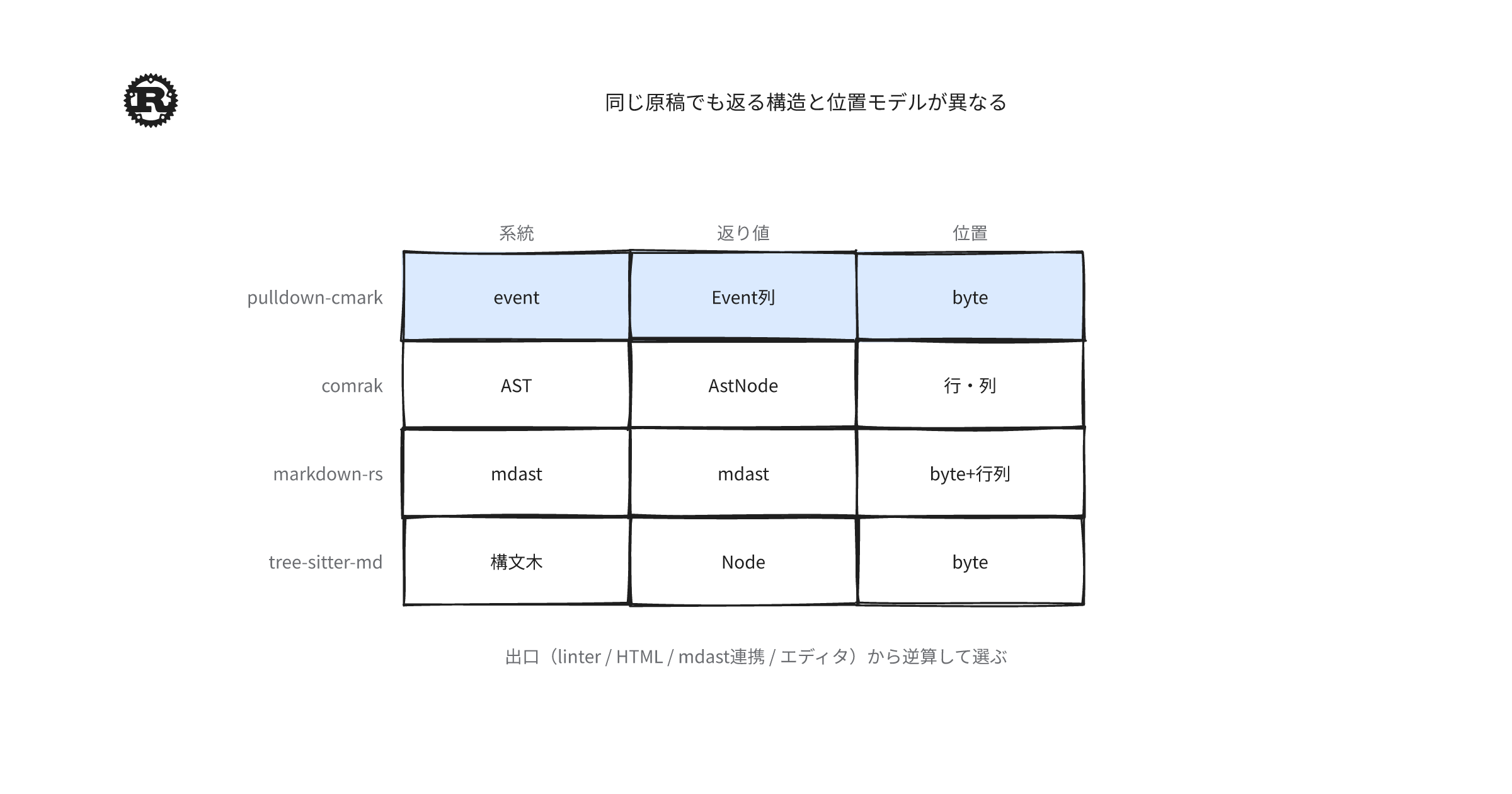
返り値は大きく分けて、pull parser(呼び出すたびに次の構造片を取り出す方式)のイベント列、AST(abstract syntax tree、抽象構文木)、mdast(Markdown abstract syntax tree、remark/unified系の中間表現)、汎用構文木(tree-sitterが返す言語非依存のノード木)の4系統に整理できる。位置情報も、byte範囲だけを返すもの、行と列だけを返すもの、両方を返すものがある。
この記事では、Rustでよく使われる4 crate(pulldown-cmark、comrak、markdown-rs、tree-sitter-md)のAPIと位置モデルの違いを整理し、出口(linter、HTML、mdast連携、エディタ)から逆算して選ぶ手順を示す。
Markdown parserが決めること
Markdown parserの仕事は、プレーンテキストを「構造つきデータ」に変換することだ。最低限、次の3点が後続処理を左右する。
- 構造の取り出し方 — 見出し / 段落 / コードブロック / リンクを、どの型で受け取るか
- 位置情報 — 原文のどのbyte、行と列に対応するか
- 拡張記法 — GFM(テーブル / タスクリスト / 打ち消し線 / autolinkなど)をどこまで解釈するか
構文木ライブラリ(rowanなど)はparserではない。parserが返した構造を、別レイヤーで木に載せ替えるのは別レイヤーの話だ。
pull parserとAST — 返り値の四系統
pull parser(呼び出すたびに次の event を取り出す方式)と、ASTやmdastのように木全体を組み立ててから処理する方式が、RustのMarkdown parserを分ける軸になる。加えてtree-sitter系は汎用構文木grammarとしてparseする。
| 系統 | 代表crate | 返り値のイメージ | 位置情報 |
|---|---|---|---|
| pull / event | pulldown-cmark | Eventのストリーム |
into_offset_iterでbyte範囲 |
| CommonMark AST | comrak | AstNode木 |
sourcepos(行と列) |
| mdast | markdown (markdown-rs) | mdastノード | byteと行・列(両方) |
| 構文木 | tree-sitter-md | 汎用syntax tree | byte範囲 |
pull parser(event列)は走査しながら処理する用途に向きやすい。ASTやmdastの木は、一度組み立ててからルールを書く用途に向きやすい。
tree-sitter-mdは別枠で、grammarを差し替えやすく、エディタ連携の文脈で選ばれることが多い。
pulldown-cmark — イベント列とbyte offset
pulldown-cmarkはCommonMark / GFMをevent列としてpullするparserだ。into_offset_iterを使うと、各eventに原文のbyte範囲(startからendまで)が付く。
use pulldown_cmark::{Event, Options, Parser};
let source = "# Heading One\n\n## Heading Two\n\n";
let parser = Parser::new_ext(source, Options::empty());
for (event, range) in parser.into_offset_iter() {
if let Event::Text(text) = event {
println!("{:?} @ {}..{}", text, range.start, range.end);
}
}
"Heading One" @ 2..13
"Heading Two" @ 18..29
見出しの開始と終了はStart eventとEnd eventで別途取れる。byte範囲は取れるが、行・列はAPI上は返さない。
GFM拡張はOptions::all()で有効化できる。テーブルやタスクリストはeventとして現れる一方、autolinkはURL文字列がText eventのまま残ることがある。
comrak — CommonMark ASTとsourcepos
comrakはCommonMark ASTを構築するparserだ。parse_documentでルートAstNodeを得て、子ノードを再帰的に走査する。sourceposはcomrakが各ノードに付ける行・列の位置で、始点と終点を行番号と列番号で表す。
use comrak::{parse_document, Arena, ComrakOptions, nodes::NodeValue};
let source = "# Heading One\n\n## Heading Two\n\n";
let arena = Arena::new();
let root = parse_document(&arena, source, &ComrakOptions::default());
for child in root.children() {
let data = child.data.borrow();
if let NodeValue::Heading(h) = &data.value {
let sp = &data.sourcepos;
println!(
"h{}: {}:{} .. {}:{}",
h.level, sp.start.line, sp.start.column, sp.end.line, sp.end.column
);
}
}
h1: 1:1 .. 1:13
h2: 3:1 .. 3:14
byte範囲は返さない。HTMLレンダリングも同梱されるが、構造抽出だけが目的ならAST走査だけで足りる。
GFM拡張はextension.*フラグで個別に有効化する。テーブル、タスク、打ち消し線、autolinkはいずれもextensionを有効にすればAST上で扱える。
markdown-rsとtree-sitter-md — mdastと構文木grammar
markdown (markdown-rs)
markdown crate(markdown-rs 1.0系)はmdastを返す。ParseOptionsのconstructsにConstructs::gfm()を指定すればGFM構文を有効化できる。入口はto_mdastで、返り値はmdast::Nodeの木だ。
use markdown::{mdast, to_mdast, ParseOptions};
let source = "# Heading One\n\n## Heading Two\n\n";
let opts = ParseOptions {
constructs: markdown::Constructs::gfm(),
..ParseOptions::default()
};
let root = to_mdast(source, &opts).expect("parse");
if let mdast::Node::Root(doc) = &root {
for node in &doc.children {
if let mdast::Node::Heading(h) = node {
let pos = node.position().expect("position");
println!(
"h{} byte {}..{} line {}:{} .. {}:{}",
h.depth,
pos.start.offset,
pos.end.offset,
pos.start.line,
pos.start.column,
pos.end.line,
pos.end.column,
);
}
}
}
h1 byte 0..13 line 1:1 .. 1:14
h2 byte 15..29 line 3:1 .. 3:15
木全体の形はおおむね次のとおり。各ノードにposition(byteのoffsetと行・列)が載る。
Root
Heading depth=1 ← "# Heading One" 全体
Text "Heading One" ← 見出しテキストだけ
Heading depth=2 ← "## Heading Two" 全体
Text "Heading Two"
Headingノードのpositionは#を含む行全体、Textノードは地の文部分だけを指す。4 parserのうち、位置モデルが最も情報量が多い。
autolinkだけ扱いが弱いことがある。本文中のbare URLがmdastのLinkとして現れないケースがあり、後段で補完が要る可能性がある。
tree-sitter-md
tree-sitterはgrammar定義から構文木を返す汎用パーサー基盤だ。エディタのハイライトや増分parseで広く使われ、言語を変えるときはgrammarだけ差し替える。Markdown専用のAST crateではなく、syntax treeエンジンにgrammarを載せた位置づけになる。
tree-sitter-mdはそのMarkdown用grammarだ。Rustからはtree_sitter crate経由でparserを組み立て、Node::kind()とbyte範囲で木を走査する。
use tree_sitter::{Node, Parser};
fn visit(node: Node, source: &str, kind: &str) {
if node.kind() == kind {
let text = node.utf8_text(source.as_bytes()).unwrap_or("");
println!(
"{} byte {}..{} {:?}",
kind,
node.start_byte(),
node.end_byte(),
text.trim_end()
);
}
for i in 0..node.child_count() {
if let Some(child) = node.child(i as u32) {
visit(child, source, kind);
}
}
}
let source = "# Heading One\n\n## Heading Two\n\nParagraph with `inline` code.\n";
let mut parser = Parser::new();
parser
.set_language(&tree_sitter_md::LANGUAGE.into())
.expect("language");
let tree = parser.parse(source, None).expect("parse");
visit(tree.root_node(), source, "atx_heading");
visit(tree.root_node(), source, "paragraph");
atx_heading byte 0..14 "# Heading One"
atx_heading byte 15..30 "## Heading Two"
paragraph byte 31..61 "Paragraph with `inline` code."
木を1段深く見ると、見出しはatx_headingの下にinline、段落もparagraphの下にinlineがぶら下がる。byte範囲は取れるが、行・列はAPI上は返さない。
document
atx_heading byte 0..14
inline byte 2..13 "Heading One"
atx_heading byte 15..30
inline byte 18..29 "Heading Two"
paragraph byte 31..61
inline byte 31..60 "Paragraph with `inline` code."
` byte 46..47 "`"
` byte 53..54 "`"
inlineのバッククォートはinline_codeノードではなく、文字ノードとして残る。リンクもinlineテキストからアプリ側で拾う必要がある場合がある。打ち消し線はgrammar定義次第で専用ノードになる。
GFMのテーブル、タスクリスト、打ち消し線、autolinkはgrammar定義次第でpipe_tableなどのノードになる。
例示原稿で見る — 構造、位置、拡張記法
# Heading One
## Heading Two
Paragraph with `inline` code.
位置モデル
| parser | byte範囲 | 行と列 | 見出しh1テキストの取り方 |
|---|---|---|---|
| pulldown-cmark | あり | なし | Text eventのslice(#は除く) |
| comrak | なし | あり | sourceposの行・列 |
| markdown-rs | あり | あり | mdast position |
| tree-sitter-md | あり | なし | 子inlineのbyte範囲(#除く) |
byte位置で指摘や修正を返すlinterなら、pulldown-cmarkとmarkdown-rsがそのまま使える。tree-sitter-mdもbyte範囲は取れるが、インライン要素によっては二次抽出が要る場合がある。行と列だけを要求するeditorなら、comrakのsourceposか、markdown-rsの両方付きpositionが扱いやすい。
GFM拡張
| 拡張 | pulldown-cmark | comrak | markdown-rs | tree-sitter-md |
|---|---|---|---|---|
| テーブル | event化 | AST + extension | mdast + GFM constructs | grammarノード |
| タスクリスト | event化 | AST + extension | mdast + GFM constructs | grammarノード |
| 打ち消し線 | event化 | AST + extension | mdast + GFM constructs | grammarノード |
| autolink | Textに残りやすい | extensionでLink | Linkにならないことがある | grammar依存 |
壊れた入力
```rust
unclosed fence
[broken link(
| parser | ふるまいの傾向 |
|---|---|
| pulldown-cmark | panicせず、block数が少なく出ることがある |
| comrak | panicせず、未閉linkを段落テキストとして残すことがある |
| markdown-rs | panicせず、未閉linkを段落テキストとして残すことがある |
| tree-sitter-md | panicせず、構文木は返る |
未閉 fence / link の例でも panic はしない。部分parseの結果をそのまま信頼するか、別途well-formedチェックを挟むかはアプリ側で決める必要がある。
ユースケース別の選定
| 用途 | 向くparser | 理由 |
|---|---|---|
| linter / 指摘位置をbyteで返す | pulldown-cmark, markdown-rs | byte範囲が直接取れる |
| HTML変換 + AST走査 | comrak | CommonMark AST + レンダラ同梱 |
| mdastエコシステムと接続 | markdown-rs | mdast出力、位置もbyte + 行・列 |
| エディタ / 増分parse / grammar差し替え | tree-sitter-md | 汎用syntax tree、grammar差し替えが容易 |
| ストリーミング走査 | pulldown-cmark | event pullでメモリ効率が良い |