Rustで日本語lintのために使用できる技術
Rustで日本語lintのために使用できる技術
コードにlintがあるように、日本語の文章にもlintをかけたくなる。表記のゆれ、消し忘れた下書きの目印、読みにくい言い回しを、人手のレビュー前に機械で拾いたい。
ところが、日本語の文章の解析では、英語向けのlinterや正規表現だけでは越えられない壁にいくつもぶつかる。素朴に正規表現へ頼ると、日本語を含む行で指摘の位置がずれる。直そうとして、原文の別の場所を壊してしまう。
この記事では、その壁を4つの課題に分けて、それぞれを「どの技術が、どんな特性で解くのか」まで説明する。
扱うのは次の4課題。
- Markdown原稿を1バイトも失わずに構造化して散文だけを位置つきで選り分ける
- 分かち書き(単語間の区切り)が無い日本語から語の境界と品詞を取り出す
- 検査した位置(原文のbyte位置)を「行と列」へ正確に変換する
- 検査結果をほかのツールが読める標準形式で出す
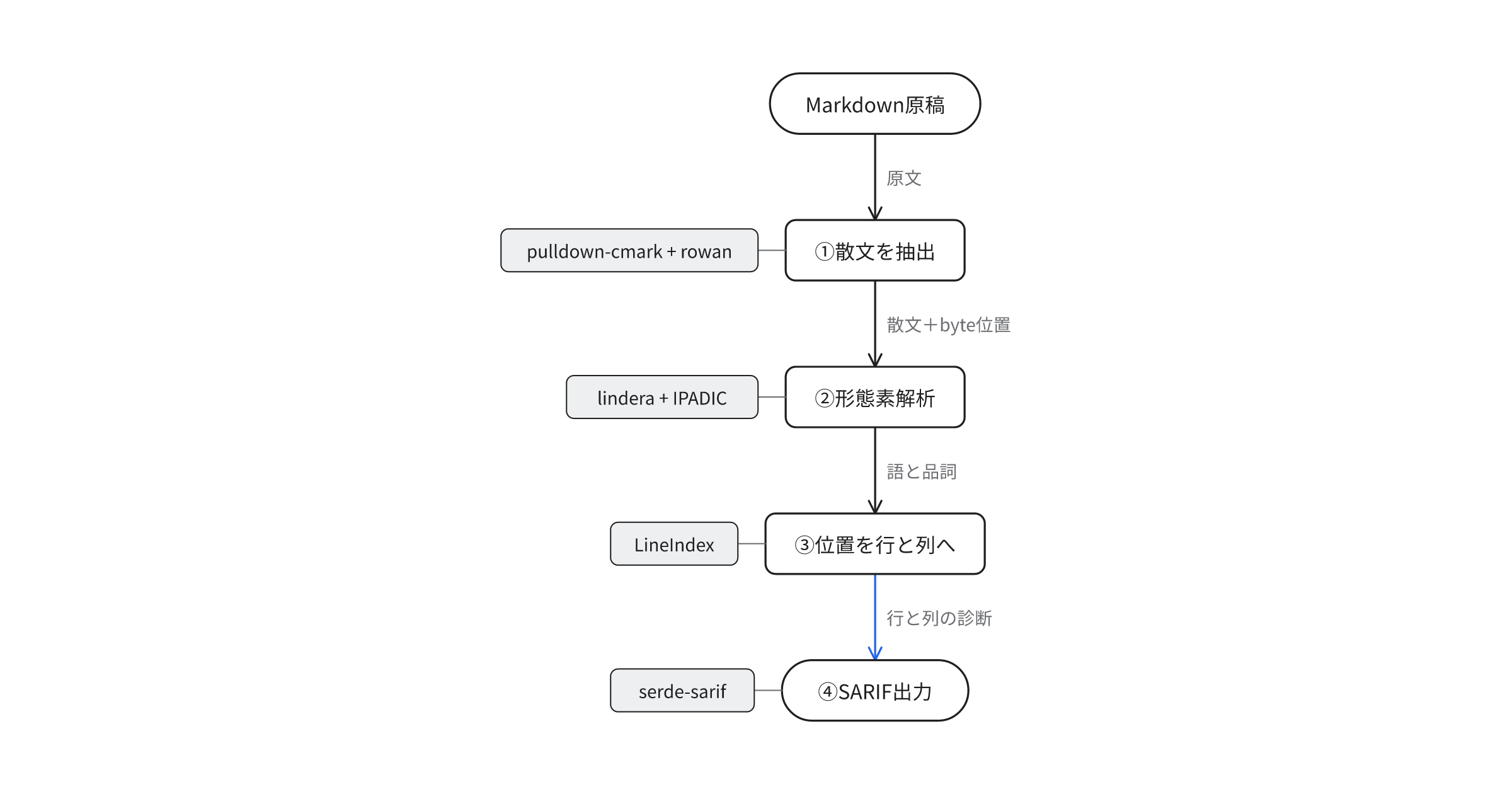
この記事を貫く軸は1つだ。この記事では、処理の各段階を層と呼ぶ。各層の出力を次の層がそのまま受け取れるか、それを軸に技術を選ぶ。その軸で選んだのが、pulldown-cmark、rowan、lindera、serde-sarifの4つだ。
全体の流れはこうなる。
pulldown-cmark + rowan"] cst --> prose["散文だけを位置つきで抽出"] prose --> morph["形態素解析
lindera + IPADIC"] prose --> rules["ルール検査"] morph --> rules rules --> diag["診断(位置・深刻度)"] diag --> sarif["SARIF 2.1.0 出力
serde-sarif"]
図中の用語(ロスレス構文木や形態素解析や診断など)は、各課題で順に説明する。以降、上流から順に4課題を見ていく。
課題1:原文を1バイトも失わずに「散文だけ」を取り出す
最初の壁は、検査対象の取り出しだ。Markdown原稿は、散文、コード、記号、構造が混ざっている。lintしたいのは地の文(散文)であって、コードブロックの中身や記号ではない。だから、まず散文だけを選り分ける必要がある。
素朴にやるなら「Markdownをプレーンテキストに変換する」だが、これだと2つの情報が失われる。1つは位置だ。たとえば# 見出しをプレーンテキストにすると見出しだけが残り、それが原文の何文字目から始まっていたかは消える。「この指摘は原文の何行目の何文字目か」を後でeditorやCIに返すには、抽出した文字が原文のどこにあったかを覚えておく必要がある。
もう1つは原文の完全性だ。空白、改行、記号といった、文章としては意味の薄い文字をまとめてtriviaと呼ぶ。このtriviaまで含めて原文を保てないと、指摘箇所を自動修正したときに周辺がずれてしまう。ここでpulldown-cmarkとrowanを組み合わせる。
pulldown-cmark:Markdownをイベント列で読む
pulldown-cmarkは、Markdownを「イベント列」として順に読むpull parserだ。「見出しが始まった」「テキストが来た」「段落が終わった」といったイベントが順番に流れてくる。into_offset_iterを使うと、各イベントに対応する原文のbyte範囲(何バイト目から何バイト目か)も一緒に取れる。byte位置とは、文字列の先頭から数えたバイト数だ。日本語は1文字が複数バイトになるため、文字数とはずれる(これを行と列へ直す話は課題3で扱う)。つまり、抽出と位置取りを同時に満たせる。
use pulldown_cmark::{Event, Options, Parser};
let source = "# 見出し\n\n本文の段落です。"; // 入力の Markdown 原稿
// Options::empty() は拡張なしの素の設定。Parser はイベントと、その原文 byte 範囲 (range) を返す。
for (event, range) in Parser::new_ext(source, Options::empty()).into_offset_iter() {
match event {
Event::Start(tag) => { /* 見出しや段落などの開始 */ }
Event::Text(_) => { /* range が、この散文の原文 byte 範囲 */ }
_ => {}
}
}
ただし、イベント列はイベントの「中身」は教えてくれても、イベントとイベントの隙間にある空白や改行までは渡してくれない。
rowan:原文を捨てない構文木
そこでrowanを重ねる。構文木とは、見出しや段落の入れ子を木で表したものを指す。rowanは、Rustでロスレス構文木(lossless syntax tree、原文を一切捨てずに復元できる構文木)を作るためのライブラリだ。rust-analyzerなどでも使われている。
木はノード(要素のまとまり)と、その葉にあたるトークン(文字列の断片)でできている。イベント列を木に組み立てるとき、イベント間の隙間バイトもtriviaトークンとして木に取り込む。こうすると「木を文字列に戻すと、元の原文と1バイトも違わず一致する」という性質を保てる。
ライブラリが渡すのは、各イベントとそのbyte範囲まで。自分で書くのは、隙間をemit_gapでtriviaとして拾い、3か所で差し込む配線だけになる。
use pulldown_cmark::{Event, Options, Parser, Tag};
use rowan::GreenNodeBuilder;
// 木のノード/トークン種別。rowan には u16 として渡す。
#[derive(Clone, Copy)]
#[repr(u16)]
enum SyntaxKind {
Document, Paragraph, Heading, // …(ノード種別。実際はもっとある)
Text, // 散文トークン
Trivia, // イベント間の空白・改行・記号
}
impl From<SyntaxKind> for rowan::SyntaxKind {
fn from(kind: SyntaxKind) -> Self { Self(kind as u16) }
}
// node_kind(tag): pulldown の Tag を SyntaxKind へ写す(Tag::Heading→Heading など)。
fn node_kind(tag: &Tag) -> SyntaxKind { /* 省略 */ SyntaxKind::Paragraph }
let source = "# 見出し\n\n本文。"; // 入力の Markdown 原稿
let mut builder = GreenNodeBuilder::new(); // rowan のロスレス木を組み立てる
builder.start_node(SyntaxKind::Document.into());
// イベント間の隙間バイトを Trivia として木に取り込む。これがロスレスの肝。
let emit_gap = |builder: &mut GreenNodeBuilder, from: usize, to: usize| {
if from < to {
builder.token(SyntaxKind::Trivia.into(), &source[from..to]);
}
};
let mut pos = 0usize;
// Options::empty(): 拡張なしの素の設定(実際は表などを有効化する)。
for (event, range) in Parser::new_ext(source, Options::empty()).into_offset_iter() {
if pos < range.start {
emit_gap(&mut builder, pos, range.start); // 直前の隙間を埋める
pos = range.start;
}
match event {
Event::Start(tag) => builder.start_node(node_kind(&tag).into()),
Event::End(_) => {
emit_gap(&mut builder, pos, range.end); // ノード末尾の余りも回収
pos = pos.max(range.end);
builder.finish_node();
}
Event::Text(_) => {
builder.token(SyntaxKind::Text.into(), &source[range.clone()]);
pos = range.end;
}
// …(コード・改行などの分岐は省略)…
_ => {
builder.token(SyntaxKind::Trivia.into(), &source[range.clone()]);
pos = range.end;
}
}
}
emit_gap(&mut builder, pos, source.len()); // 末尾の余りも取り込む
散文を選り分ける
この構造化を踏まえて、検査対象の散文を選り分ける。段落と見出しの中のテキストだけを集め、コードブロックの中身やインラインコードは集めない。こうしておくと、コード例の中の表記は検査対象に入らない。たとえばinlineコードとコードブロックを含む段落を通すと、地の文だけが残る。
let source = "段落に `inline` を含む。"; // 入力の Markdown
// prose_runs: 段落・見出しの Text トークン(地の文)だけを byte 位置つきで集める。
for run in prose_runs(&parse(source)) {
// run.text = 散文、run.start = 原文の byte 位置
}
入力:
段落に `inline` を含む。
(続けてコードブロック: let code = 1;)
抽出される散文:
段落に を含む。 (`inline` の中身もコードブロックも落ちる)
代替と限界
代替も見ておく。Markdown parserにはcomrakもあるが、こちらが返す位置情報は行・列(sourcepos)のみで、原文のbyte範囲を直接は返さない。この構成はbyte範囲を起点に原文をロスレスに組み立て、自動修正もその範囲で行う。行・列しか得られないと、byte単位の復元や修正へ直接はつなげられず、行・列からbyte位置へ逆算する層を挟むことになる。
markdown-rsは表現力に富むものの、まだ1.0前で安定途上だ。ロスレス構文木の側もrowan一択ではなく、cstreeなどの選択肢がある。判断軸は「原文のbyte位置を取れるか」「原文を欠落なく保てるか」「将来の自動修正やエディタ連携で木を再利用できるか」だ。
限界もある。rowanは構文木の器であって、Markdownを解釈してくれるわけではない。どの文字をトークンにし、どのノードを見出しや段落とみなすかは、pulldown-cmark側と自分の設計で決める必要がある。たとえばインラインコードの範囲を取り違えると、codeの中身まで散文として拾い、本来検査しない識別子に指摘が出る。
課題2:分かち書きの無い日本語から、語の境界と品詞を取り出す
散文を取り出せたら、次は中身の解析に移る。英語なら空白で単語が区切られているので、split(' ')でおおよそ語に分けられる。日本語にはこの区切りが無い。「日本語を解析する」のどこで語が切れるかは、文字を見ただけでは決まらない。
正規表現でも厳しい。たとえば「書く」という動詞は、文中では「書か」「書き」「書け」と形を変える(活用する)。正規表現でこれらを同じ語として束ねたり、品詞(名詞か動詞かなど)を判定したりはできない。送り仮名のゆれ(「行う」と「行なう」)、漢字とかなのゆれ(「事」と「こと」)、文の区切り(句点と括弧や小数点が混ざる)も、パターンだけでは安定して扱えない。
lindera + IPADIC:形態素解析で語と品詞を取る
ここで形態素解析の出番になる。形態素解析は、文を意味を持つ最小単位(形態素)に分け、それぞれの品詞や原形(基本形)を与える処理を指す。本記事では、この最小単位を「語」とも呼ぶ。形態素は解析器が決める単位で、人間の単語感覚とそのまま一致するとはかぎらない。
Rustではlinderaがこの役割を担える。linderaはRust製の形態素解析器で、辞書を使って日本語を語に分ける。辞書にはIPADICを使い、embed-ipadic機能でコンパイル時にバイナリへ焼き込む。こうすると、実行時に外部の辞書ファイルを配らなくてよく、単一の実行ファイルだけで動く(CLIやDocker imageとして配りやすい)。
素性とは、品詞や基本形といった語に付く属性を指す。辞書の読み込みから語の分割までがlinderaのAPIで、自分で書くのは各語の素性を読むループだけだ。
use lindera::dictionary::load_dictionary;
use lindera::mode::Mode;
use lindera::segmenter::Segmenter;
use lindera::tokenizer::Tokenizer;
let text = "日本語を解析する"; // 解析対象の地の文(散文ラン 1 つぶん)
// "embedded://ipadic" は、コンパイル時に焼き込んだ辞書を指す。
let dictionary = load_dictionary("embedded://ipadic")?;
let segmenter = Segmenter::new(Mode::Normal, dictionary, None);
let tokenizer = Tokenizer::new(segmenter);
for mut token in tokenizer.tokenize(text)? {
// details() は IPADIC の素性配列を返す:
// [品詞, 細分類1, 細分類2, 細分類3, 活用型, 活用形, 基本形, 読み, 発音]
let details: Vec<String> = token.details().into_iter().map(ToString::to_string).collect();
// token.surface(表層形)と token.byte_start(原文 byte 位置)も使える。
}
実際に「設計メモ」を解析させると、語ごとに品詞、基本形、読みが取れる。
morphology sample [設計メモ]:
設計 品詞=名詞 基本形=設計 読み=セッケイ
メモ 品詞=名詞 基本形=メモ 読み=メモ
品詞で書くルール:形式名詞の仮名書き
品詞が取れると、正規表現では書けないルールが書ける。例として、「形式名詞は仮名書きが読みやすい」というルールを考えてみる。形式名詞は「こと」「もの」のように具体的な意味の薄い名詞で、非自立は単独では文の骨格になりにくいことを指す。「この文章を解析する事には」の「事」は、それ自体に具体的な意味を持たない形式名詞(品詞は名詞、細分類は「非自立」)で、仮名書きが好まれる。一方で「事件」「人事」は一語の名詞として切り出され、表層は「事」にならない。
まず語の区切りが、複合語の中の「事」と、独立した「事」を分ける。その独立した「事」から形式名詞だけを拾うのに、非自立という細分類が効く。表層の文字だけを見る正規表現では、このどちらもできない。
// 形態素 1 つ。lindera が返す素性のうち、ルールで使う分だけ持つ。
struct Morph {
surface: String, // 表層形(原文に現れた文字列。例:「事」)
pos: String, // 品詞(例:「名詞」「動詞」)
pos_detail_1: String, // 細分類1(例:「非自立」)
}
// 仮名書きを促す対象の形式名詞。
const FORMAL_NOUNS: &[&str] = &["事", "物", "為", "時", "所"];
let is_formal_noun = morph.pos == "名詞"
&& morph.pos_detail_1 == "非自立"
&& FORMAL_NOUNS.contains(&morph.surface.as_str());
代替と限界
代替の形態素解析器もある。vibratoは高速だが辞書を実行時にファイルから読むため、単一バイナリで配りたいときには向かない。sudachiは複合語の分割に強いが、その分だけ扱いが複雑になる。MeCabは定番だがC実装で、RustからはFFI(外部関数インタフェース)越しの呼び出しになる。lindera + IPADICを選ぶのは、辞書を埋め込めて単一バイナリを保て、品詞の細分類まで取れて活用形の判定に足りるからだ。
限界もはっきりしている。形態素解析の結果は辞書と分割モードに依存する。専門用語や新語は期待どおりに分割されないことがある(辞書に無い造語は1語にまとまらず、数文字ずつに割れて品詞も付かないことがある)。そして、品詞は取れても、その表現の良し悪しまでは判定しない。形態素解析が出すのは、あくまで検査ルールの材料となる事実だ。
課題3:検査位置を原文の「行と列」へ正確に戻す
語を取り出せても、指摘を返す位置がずれていては使えない。ここに日本語特有の落とし穴がある。Rustの文字列はUTF-8(Unicodeのbyte符号化方式)のbyte列で、日本語の1文字は複数byteを占める。一方、エディタやCIが求めるのは、「何文字目」という文字基準の行・列になる。
なお、LSP〔Language Server Protocol、エディタと言語ツールをつなぐ規約〕では、UTF-16単位で数えることもある。一部のエディタは内部でUTF-16を使うため、文字数とは別の数え方になる。byteの位置をそのまま列番号として返すと、日本語を含む行で位置が大きくずれる。しかも、複数のルールが同じ変換を何度も引くので、毎回先頭から数え直すと遅い。
LineIndex:byte位置を行と列へ
位置の変換はLineIndexで解く。最初に「各行が原文の何byte目から始まるか」の表を1度だけ作る。二分探索は、昇順に並んだ表から目的の行を高速に探す手法だ。位置を引くときは、その表を二分探索(partition_point)して行番号を求め、列はbyte差ではなく文字数(chars().count())で数える。
// 原文中の 1-based な行・列。
pub struct Position { pub line: usize, pub column: usize }
// byte offset を行・列へ写す索引。
pub struct LineIndex<'a> {
source: &'a str, // 原文
line_starts: Vec<usize>, // 各行が始まる byte 位置(昇順)
}
impl LineIndex<'_> {
pub fn position(&self, offset: usize) -> Position {
// 「行頭 byte <= offset」を満たす行頭の数が、そのまま 1-based の行番号になる。
let line = self.line_starts.partition_point(|&start| start <= offset);
let line_start = self.line_starts[line - 1];
// 列は byte 差でなく文字数で数える(日本語のマルチバイト対応)。
let column = self
.source
.get(line_start..offset)
.map_or(1, |slice| slice.chars().count() + 1);
Position { line, column }
}
}
行頭の表を作るコストは最初の1回だけで、以降の位置引きは二分探索のぶんしかかからない。
代替と限界
代替として、rust-analyzer由来のline-indexやropeyなど、既製の位置インデックスもある。今回は依存を増やさず、標準ライブラリのpartition_pointとchars().count()で足りる範囲なので自前にした。毎回先頭から数え直す素朴な実装は、ルール数が増えると同じ走査が積み上がって遅い。
限界もある。文字数で数える列は、UTF-16単位を求める連携先(LSPなど)とはまだズレる。サロゲートペアとは、絵文字などで見た目1文字が内部では2単位になるものだ。たとえばサロゲートペアになる絵文字を1つ含む行では、chars().count()とUTF-16で列が1つずれ、エディタの波線が1文字ぶんずれる。結合文字や異体字セレクタを「1文字」と数えるかも、用途によって決め直す必要がある。
ルール検査の層
課題1〜3で、散文、品詞、位置の3つがそろう。これらを突き合わせて違反を判定するのがルール検査だ。たとえば「形式名詞は仮名書き」のルールは、課題2の品詞で対象を見つけ、課題1や課題3の位置から違反箇所を指す。
各ルールは、見つけた違反を診断として出す。診断とは、違反1件ぶんの指摘を指す。位置、メッセージ、重要度(severity)を持ち、重要度はerrorやwarningなどの度合いを表す。
課題4:検査結果を、ほかのツールが読める標準形式で出す
最後は出口の話。検査結果は、読み手によって必要な形が違う。
- 人が内容を読む
- CIが合否を出す
- エディタが波線を引く
- ほかのツールが結果を集める
独自のJSONで出すと、読み手ごとに変換層を書く羽目になる。
SARIF:静的解析結果を運ぶ標準形式
そこで標準形式のSARIFを使う。SARIF(Static Analysis Results Interchange Format)は、静的解析の結果を交換するためのOASIS標準だ。結果をJSONで表すので、ツール間で共通の形として受け渡せる。GitHubのcode scanningはこれを直接読み、errorは赤、warningは黄で原稿上に表示する。
serde-sarif:型付きでSARIFを書く
Rustではserde-sarifが、SARIFの各要素を型付きの構造体として提供する。これを組み立ててJSONにすれば、出力フォーマットの細部を自前で抱えなくて済む。
use serde_sarif::sarif::{ArtifactLocation, Location, Message, PhysicalLocation, Region, Result as SarifResult};
// diagnostic: ルール検査が出した指摘 1 件(rule_id / message / severity / byte 位置)。
// index: 前掲の LineIndex。byte 位置を 1-based の行・列へ写す。
// file: 検査した原稿のパス。level(sev): Severity を SARIF の level(error/warning)へ。
let start = index.position(diagnostic.start);
let end = index.position(diagnostic.end);
let region = Region::builder()
.start_line(start.line as i64)
.start_column(start.column as i64)
.end_line(end.line as i64)
.end_column(end.column as i64)
.build();
let location = Location::builder()
.physical_location(
PhysicalLocation::builder()
.artifact_location(ArtifactLocation::builder().uri(file.to_string()).build())
.region(region)
.build(),
)
.build();
SarifResult::builder()
.rule_id(diagnostic.rule_id.clone())
.level(level(diagnostic.severity)) // error / warning
.message(Message::builder().text(diagnostic.message.clone()).build())
.locations(vec![location])
.build()
出力例
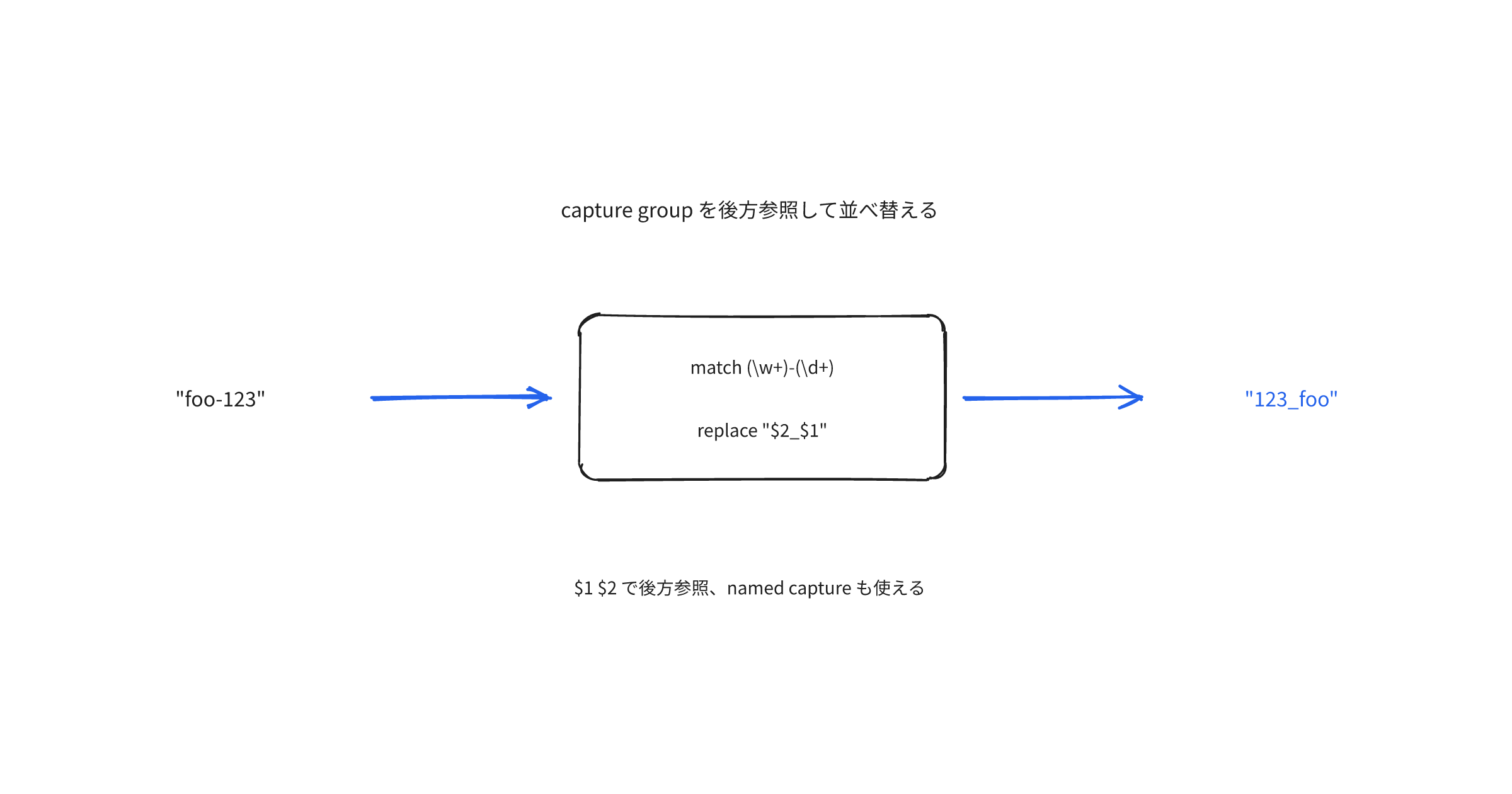
例として、簡単なルールを2つ用意して検査してみる。1つは、未完了マーカ(あとで消す目印)を本文に残さないルール。もう1つは、課題2で触れた「形式名詞は仮名書き」のルール。
# 設計メモ
この文章を解析する事には、いくつかの課題がある。TODO で後述する。
この原稿では、未完了マーカが3行目の25文字目から始まる。課題1〜3で取り出したこの位置が、そのままSARIFのstartLine 3・startColumn 25として出力される。
{
"level": "error",
"locations": [
{
"physicalLocation": {
"artifactLocation": { "uri": "data/article.md" },
"region": { "startLine": 3, "startColumn": 25, "endLine": 3, "endColumn": 29 }
}
}
],
"message": { "text": "未完了マーカ TODO が本文に残っている" },
"ruleId": "todo-marker"
}
人が読むためのテキスト出力も、同じ検査結果から出している。
prose runs: 4
diagnostics: 2
3:25 [todo-marker] 未完了マーカ TODO が本文に残っている
3:10 [formal-noun-kana] 形式名詞「事」は仮名書きが読みやすい
代替と限界
代替は独自JSONだが、各ツールに変換層を強いるうえ、複数形式を併用すると互換性の検証が増える。限界もある。SARIFは結果を運ぶ形式であって、結果の正しさは保証しない。たとえば列を1つ取り違えた診断を出すと、SARIFはそれをそのままGitHubやエディタへ渡し、無関係な隣の文字に波線が引かれる。文章レビューの会話や代替表現の比較といった人間同士のやり取りを載せるには重く、そこは別の手段に分けるほうが扱いやすい。
まとめ:層ごとの入出力で技術を選ぶ
4つの課題を分けて見ると、日本語の文章lintは「原稿 → 抽出 → 解析 → 検査 → 出力」という小さなパイプラインになる。
| 課題 | 解く技術 | 効かせる特性 | 主な代替 |
|---|---|---|---|
| 原文を失わず散文抽出 | pulldown-cmark + rowan |
byte位置つきイベント+ロスレス構文木 | comrak / markdown-rs / cstree |
| 語境界、品詞 | lindera + 埋め込みIPADIC |
単一バイナリ + 品詞、活用形の素性 | vibrato / sudachi / MeCab |
| 位置を行と列へ | LineIndex |
二分探索による行 + 文字数ベースの列 | 素朴な毎回計算 |
| 結果連携 | SARIF + serde-sarif |
OASIS標準+型付き生成 | 独自JSON |
この4課題を通すと、技術選定の軸は1つに絞れる。ある層が返す情報(byte位置、品詞、行・列、severity)を、次の層がそのまま受け取れるかだ。抽出がbyte位置を返すのに後段が文字数として扱えば位置はずれる。形態素の境界がルールの単位と合わなければ、同じ語を拾ったり逃したりする。入口と出口の形をそろえておけば、技術の差し替えも、壊れたときの切り分けも層の中で閉じる。
最後に、静的解析の限界にも触れておく。ここで扱ったのは、文字、語、位置、形式という機械的に決まる事実でしかない。論理が飛んでいないか、抽象と具体がつながっているかといった「文章の良し悪し」は、形態素解析や正規表現では測れない。その判断は、別の手段(人手のレビューや言語モデルの助言)に委ねる。それでも、機械で確実に拾える4課題を先に固めておけば、人手のレビューを機械では測れない判断に向けやすくなる。