rowanでロスレス構文木を作る — 原文を捨てない構文表現と使い方
rowanでロスレス構文木を作る — 原文を捨てない構文表現と使い方
ソースを整形し直すフォーマッタ、指摘箇所を原文の正しい位置へ重ねるlinter、カーソル位置から構文を引くエディタ。どれも、構文木から原文へ正確に戻れることを前提にする。ところが、構文解析の教科書的な成果物である抽象構文木(AST、abstract syntax tree)は、空白やコメント、元の位置を捨てる。捨てた木の上では、整形でコメントが消え、指摘の位置が1文字ずれ、一部を直したつもりで別の箇所を壊す。
rowanは、この問題を構文木の側で解くRustのライブラリ。原文を1バイトも捨てずに構造へ載せ、各ノードが原文のどこから来たかという位置まで保つ。空白や記号は木のどこかに必ず残り、走査してもいつでも原文へ戻れる。rust-analyzerがこの設計を採用し、原文を保ちたい他の道具にも応用できる。以下では、Markdownを題材に、rowanの設計と使い方を動く最小コードで追う。
抽象構文木が捨てる情報と、それが要る場面
ふつうのASTが落とすもの
構文解析の教科書的な成果物は抽象構文木(AST、abstract syntax tree)と呼ばれる。抽象という名のとおり、意味の解釈に要らない情報を落とす。インデントの量、コメント、括弧の有無、トークン間の空白、各要素が原文の何バイト目から始まるかは、たいてい残らない。式1 + 2を「加算ノードに子が2つ」とだけ持てば、評価や型検査には足りる。
落としてよいのは、原文から情報を取り出すことが目的のすべてである場合に限る。コンパイラのようにソースを読んで機械語へ変換し、元のテキストへ戻らないなら、空白やコメントは用済みになる。
失われると何が困るか
原文へ戻る道具では、落とした情報がそのまま品質を決める。
| 用途 | 失われると困ること |
|---|---|
| フォーマッタ | 整形後にコメントや文字列の中身を保てない |
| エディタとlinter | 指摘や補完をカーソル位置へ重ねられない |
| コード変換(codemod) | 触らない箇所の体裁が1バイト動いてしまう |
正規表現や行単位の処理でこれをやると、日本語のように1文字が複数バイトになるテキストで位置がずれ、直そうとして別の箇所を壊す。構造を跨いだ置換になるほど破綻しやすい。原文を保ったまま構造と位置の両方を引ける表現があれば、この問題は構造の側で解ける。それがロスレス構文木(lossless CST、concrete syntax tree)であり、rowanはその実装を与える。
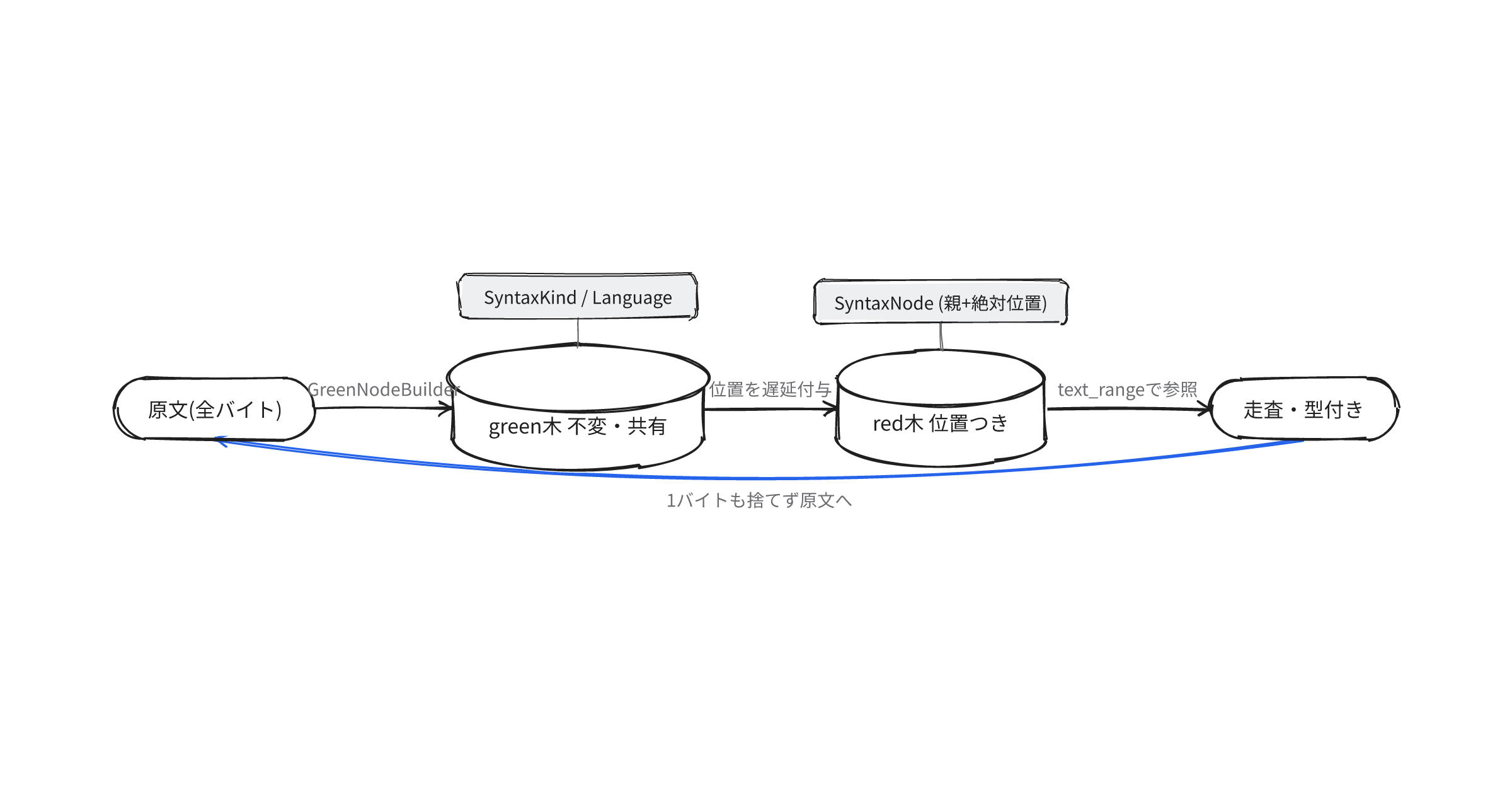
greenとredの二層構造
rowanは木を2つの層に分ける。greenと呼ぶ不変の木に構造とテキストを持たせ、redと呼ぶ参照ビューに親への道と原文上の絶対位置を持たせる。
不変・位置なし・構造を共有"] green --> red["red tree (SyntaxNode)
親ポインタ・絶対オフセット"] red --> walk["走査・型付きビュー・位置写像"]
greenは位置を持たない不変の木
greenの木が持つのは、種別と、子(部分木かトークン)と、トークンなら原文の文字列だけ。絶対位置は持たない。データ構造としては、おおよそ次の形になる。
green のトークン = 種別 + 原文の文字 例: Text "x"
green のノード = 種別 + 子の並び 例: Paragraph -> [Text, 改行]
位置を持たないことが効く。同じ種別で同じ文字のトークンは、メモリ上の1つの実体にまとめて共有できる。greenは不変なので、共有しても書き換えで壊れない。
redは親と絶対オフセットを遅延でかぶせる
greenだけでは、この段落が原文の何バイト目か、親は何かを引けない。redの層は、greenのノードを指しながら、親へのポインタと先頭からの累積オフセットを加える。rowanではノードをSyntaxNode、葉をSyntaxTokenとして扱う。
red のノード = green への参照 + 範囲 + 親 例: Paragraph @0..2, 親 Document
redノードは必要なときに遅延生成され、greenの共有を壊さない。SyntaxNodeは親と兄弟と子をたどれ、text_range()で原文上のバイト範囲を返す。
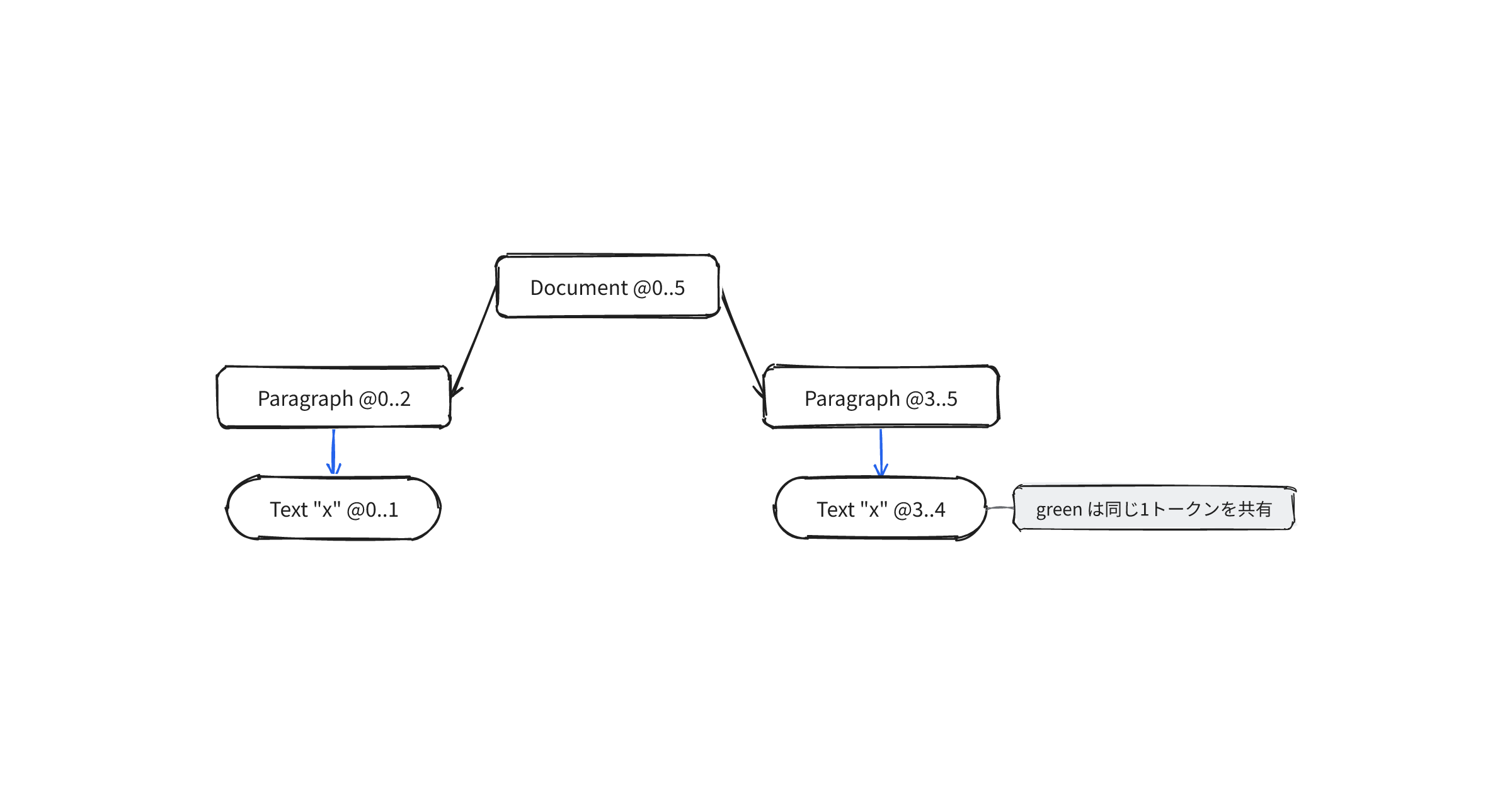
二層の違いは、同じ文字が2回出る入力を解析すると見える。x\n\nx\nを解析し、各ノードに範囲をつけて出すと次のようになる。
Document @0..5
Paragraph @0..2
Text "x" @0..1
Trivia "\n" @1..2
Trivia "\n" @2..3
Paragraph @3..5
Text "x" @3..4
Trivia "\n" @4..5
2つのText "x"は、green層では同じ1つのトークンを共有できる。redのほうは、それぞれに@0..1と@3..4という別の位置を与える。形と文字はgreenが1つ持ち、位置だけをredが各自に配る。この分担が二層構造の核。
なぜ二層に分けるのか
絶対位置を全ノードに持たせる素朴な木は、同型の部分木でも位置が違えば別物になり、共有できない。木が大きいほど重くなり、一部を編集しただけで全体を作り直しやすい。greenを位置から切り離すと、構造の共有と部分的な再利用が効く。その上にredで位置をかぶせれば、利用者は重さを意識せずに位置を引ける。rust-analyzerが巨大なRustプロジェクトを扱いながら編集に追従できるのは、この分離が土台にある。
SyntaxKindとLanguageトレイトで種別を定義する
rowanは特定の言語を知らない。木に載るノードやトークンの種類、たとえば見出しや段落、テキストといった区別を、利用者がu16の列挙として定義する。この列挙を種別(SyntaxKind)と呼ぶ。種別を、rowanが内部で持つu16の値とLanguageトレイトで変換すれば、任意の文法をrowanに載せられる。
u16の列挙で種別を表す
種別は#[repr(u16)]を付けた列挙として定義する。各値がrowanの内部表現であるu16に一対一で対応する。Markdownを載せる今回の種別は次のとおり。
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Hash)]
#[repr(u16)]
pub enum SyntaxKind {
// ノード(子を持つ)
Document = 0,
Paragraph,
Heading,
BlockQuote,
List,
Item,
CodeBlock,
Link,
Strong,
// トークン(葉)
Text,
Code,
Break,
Trivia,
}
impl From<SyntaxKind> for rowan::SyntaxKind {
fn from(kind: SyntaxKind) -> Self {
Self(kind as u16)
}
}
rowan::SyntaxKindはu16をくるんだだけの型。Fromを実装しておくと、後で木を組み立てるときにSyntaxKind::Heading.into()と書ける。空白や記号など構文の意味を持たない断片はTriviaという一種別にまとめる。これを用意することが、後で原文を捨てない鍵になる。
言語非依存なrowanに自分の文法を載せる
Languageトレイトは、自分で定義したSyntaxKindを、rowanが内部で持つu16の値へ変換し、また元へ戻す。値を持たない列挙ProseLangを言語の印として定義し、それにLanguageを実装する。
use rowan::Language;
// 値を持たない。rowan に「この木はこの文法だ」と伝える印として使う。
pub enum ProseLang {}
impl Language for ProseLang {
type Kind = SyntaxKind;
fn kind_from_raw(raw: rowan::SyntaxKind) -> SyntaxKind {
use SyntaxKind::*;
match raw.0 {
0 => Document,
1 => Paragraph,
2 => Heading,
// 中略: 各値を列挙の変種へ
_ => Trivia,
}
}
fn kind_to_raw(kind: SyntaxKind) -> rowan::SyntaxKind {
kind.into()
}
}
// 以降、利用者はこの型エイリアスを通して木を扱う。
pub type SyntaxNode = rowan::SyntaxNode<ProseLang>;
pub type SyntaxToken = rowan::SyntaxToken<ProseLang>;
kind_from_rawはu16から列挙へ戻す関数。未知の値をTriviaに倒しておくと、想定外の種別が来ても木が壊れない。ProseLang自体は値を持たないので実行時のコストはなく、型の上でこの木はMarkdownの木だと示すだけに働く。
GreenNodeBuilderで原文を捨てずに組み立てる
木はGreenNodeBuilderで作る。3つの操作を順に呼ぶだけでよい。
| 操作 | 働き |
|---|---|
start_node(kind) |
ノードを開く |
token(kind, text) |
葉(トークン)を足す |
finish_node() |
開いたノードを閉じる |
入れ子は、開いている間に別のノードを開けば作れる。最後にfinish()を呼ぶとgreenの木が返り、SyntaxNode::new_rootでそれをredの根に包む。

隙間のバイトをtriviaとして回収する
Markdownの解析にはpulldown-cmarkを使う。これは「ここから段落」「ここはテキスト」といった構造のイベントを、各イベントが対応する原文のバイト範囲とともに返す。ただし、イベントとイベントの隙間にある空白や記号はイベントにならない。この隙間をTriviaトークンとして残らず拾うと、原文の全バイトが木のどこかに必ず入る。
use pulldown_cmark::{Event, Options, Parser};
use rowan::GreenNodeBuilder;
pub fn parse(source: &str) -> SyntaxNode {
let mut builder = GreenNodeBuilder::new();
builder.start_node(SyntaxKind::Document.into());
// イベントが触れなかったバイトを Trivia として拾う。
let emit_gap = |builder: &mut GreenNodeBuilder, from: usize, to: usize| {
if from < to {
builder.token(SyntaxKind::Trivia.into(), &source[from..to]);
}
};
let mut pos = 0usize;
for (event, range) in Parser::new_ext(source, Options::empty()).into_offset_iter() {
if pos < range.start {
emit_gap(&mut builder, pos, range.start); // 直前の隙間を回収
pos = range.start;
}
match event {
Event::Start(tag) => builder.start_node(node_kind(&tag).into()),
Event::End(_) => {
emit_gap(&mut builder, pos, range.end);
pos = pos.max(range.end);
builder.finish_node();
}
Event::Text(_) => {
builder.token(SyntaxKind::Text.into(), &source[range.clone()]);
pos = range.end;
}
// Code や改行など他のイベントも同様にトークン化する
_ => {
builder.token(SyntaxKind::Trivia.into(), &source[range.clone()]);
pos = range.end;
}
}
}
emit_gap(&mut builder, pos, source.len()); // 末尾の余りも回収
builder.finish_node();
SyntaxNode::new_root(builder.finish())
}
node_kindは、pulldown-cmarkのタグをSyntaxKindへ写すだけの小さな関数。段落ならParagraph、見出しならHeadingを返す。要点は、テキストやコード、改行、そして隙間のバイトまで、すべて何らかのトークンとしてbuilder.tokenに渡るところ。次のMarkdownをparseに通してみる。
# rowan の構文木
本文の段落に `inline code` と [リンク](https://example.com) と **強調** を含む。
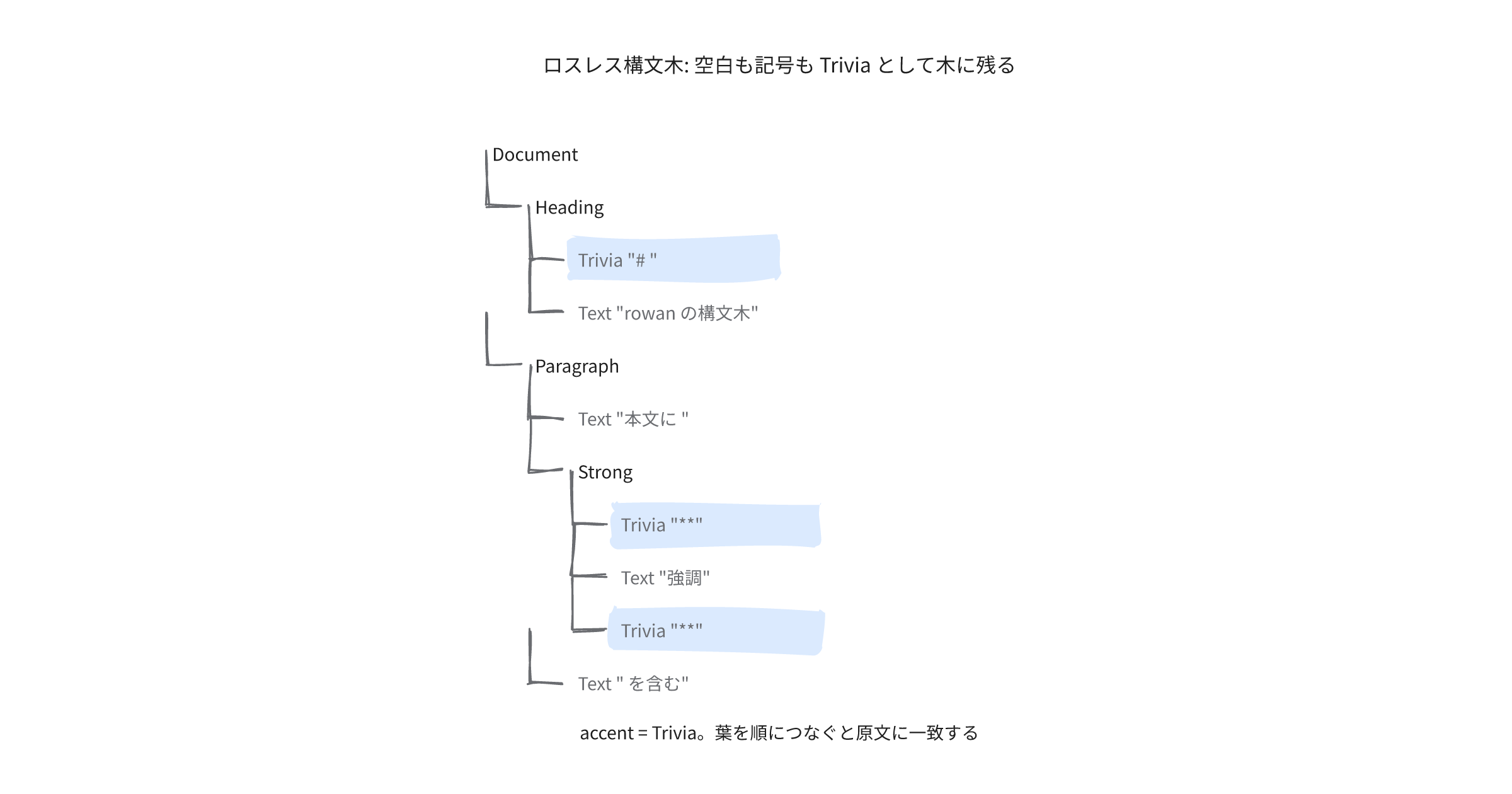
得られる木はこうなる。空白や記号がすべてTriviaとして残り、各葉が原文の断片を保持している。
Document
Heading
Trivia "# "
Text "rowan の構文木"
Trivia "\n"
Trivia "\n"
Paragraph
Text "本文の段落に "
Trivia "`"
Code "inline code"
Trivia "`"
Text " と "
Link
Trivia "["
Text "リンク"
Trivia "](https://example.com)"
Text " と "
Strong
Trivia "**"
Text "強調"
Trivia "**"
Text " を含む。"
Trivia "\n"
すべての葉のテキストを順につなぐと、元の原文に1バイト違わず一致する。この往復一致parse(src).text() == srcこそ、ロスレスの定義そのもの。木をどう走査しても、いつでも原文へ戻れる土台がここで整う。
木を歩いてノードとトークンを走査する
redの木は、親と子と兄弟をたどる走査メソッドを備える。代表的なものを使い分ける。
| メソッド | 役割 |
|---|---|
descendants() |
自分以下のノードを深さ優先で返す |
children_with_tokens() |
直下の子をノードとトークン混在で返す |
ancestors() |
自分から根へ向かって親をたどる |
descendants()で見出しだけを集め、それぞれの原文上の開始位置を引く例を示す。
use crate::cst::{SyntaxKind, SyntaxNode};
// 見出しノードを (開始バイト, 見出しの原文) の組で集める。
pub fn headings(root: &SyntaxNode) -> Vec<(usize, String)> {
root.descendants()
.filter(|node| node.kind() == SyntaxKind::Heading)
.map(|node| {
let start = usize::from(node.text_range().start());
(start, node.text().to_string())
})
.collect()
}
先ほどの木に対してheadingsを呼ぶと、見出しが原文の0バイト目から始まると分かる。
heading@0: # rowan の構文木
バイト範囲から原文へ戻る
各ノードとトークンはtext_range()でバイト範囲を返し、トークンはtext()で原文の断片を返す。TextRangeの端はusizeへ変換でき、そのまま&source[start..end]の添字に使える。散文だけを位置つきで取り出す例を示す。
use crate::cst::{SyntaxKind, SyntaxNode};
pub struct ProseSpan {
pub start: usize,
pub end: usize,
pub text: String,
}
pub fn prose_spans(root: &SyntaxNode) -> Vec<ProseSpan> {
root.descendants_with_tokens()
// ノードとトークンの混在から、トークンだけを取り出す
.filter_map(|element| element.into_token())
.filter(|token| token.kind() == SyntaxKind::Text)
.map(|token| {
let range = token.text_range();
ProseSpan {
start: usize::from(range.start()),
end: usize::from(range.end()),
text: token.text().to_string(),
}
})
.collect()
}
実行すると、各散文片が原文のどの範囲かが取れる。返ってきた範囲で原文を切り出すと、トークンのテキストに必ず一致する。
prose[2..20]: "rowan の構文木"
prose[22..41]: "本文の段落に "
prose[60..69]: "リンク"
prose[98..104]: "強調"
prose[160..202]: "引用の中の文も同じ木に載る。"
リンクや強調の中の文字まで、装飾の記号を除いた散文として、原文上の正確な位置とともに引けている。指摘や注釈を原文へ重ねる処理は、この位置を使う。
型付きビューで素の木に意味を与える
SyntaxNodeは便利だが、種別がu16でしかないため、これは見出しだ、見出しのレベルはいくつだ、といった意味はコードに現れない。rust-analyzerと同じやり方で種別ごとのラッパ型をかぶせると、型の上で意味を扱える。
種別ごとのラッパを作る
素のノードから型付きビューへ変換できることを表すトレイトを1つ用意する。castは種別が合えばSome、合わなければNoneを返す。
use crate::cst::{SyntaxKind, SyntaxNode};
pub trait AstNode {
fn cast(node: SyntaxNode) -> Option<Self>
where
Self: Sized;
fn syntax(&self) -> &SyntaxNode;
}
// 見出しの型付きビュー。
pub struct Heading {
syntax: SyntaxNode,
}
impl AstNode for Heading {
fn cast(node: SyntaxNode) -> Option<Self> {
(node.kind() == SyntaxKind::Heading).then_some(Heading { syntax: node })
}
fn syntax(&self) -> &SyntaxNode {
&self.syntax
}
}
impl Heading {
// 見出しレベル。先頭の '#' の数を原文から数える。
pub fn level(&self) -> usize {
self.syntax
.text()
.to_string()
.chars()
.take_while(|&c| c == '#')
.count()
}
// 見出しの本文。記号や空白を除いた Text トークンを連結する。
pub fn text(&self) -> String {
self.syntax
.descendants_with_tokens()
.filter_map(|element| element.into_token())
.filter(|token| token.kind() == SyntaxKind::Text)
.map(|token| token.text().to_string())
.collect()
}
}
### 深い見出しをcast経由で扱うと、level()が3、text()が「深い見出し」を返す。記号の数えやトークンの連結という細部がHeadingの内側に隠れ、呼ぶ側は意味のある操作だけを見る。最初の例の見出しに対しては次のようになる。
typed heading: level=1, text="rowan の構文木"
素の木と型付き層を使い分ける
型付きビューはgreenとredを作り直さない。syntax()で元のノードへいつでも戻れるので、位置や走査が要る処理は素の木に、意味が要る処理は型付き層にと役割を振り分けられる。種別ごとにラッパ型を増やしていけば、文法全体に型付きのAPIをかぶせられる。rust-analyzerはこの層をコード生成で量産している。
checkpointとエラー回復と位置の永続化
ここまでで木の組み立てと利用は一通りそろう。実際のツールでは、もう一段の道具が効く。後から子を包むcheckpoint、位置を保存して再解析後に引き当てるSyntaxNodePtr、壊れた入力でも木を組み切るエラーノードの3つ。いずれも手書きのパーサで顕著に効くので、最小の式言語で示す。扱うのは整数と演算子+、*と空白だけ。
checkpointで後付けノードを作る
1 + 2 * 3のような左結合の二項演算では、左辺を読み終えた時点で、それが単独の項か、より大きな式の左側かが決まらない。+が来て初めて、さきほど読んだ左辺を加算ノードの子として包みたくなる。checkpoint()は木のその位置に印を置き、start_node_at(checkpoint, kind)で、印より後に積んだものを後からノードで包む。
use rowan::GreenNodeBuilder;
struct Parser<'a> {
tokens: Vec<(ExprKind, &'a str)>,
pos: usize,
builder: GreenNodeBuilder<'static>,
}
impl<'a> Parser<'a> {
fn expr(&mut self) {
let checkpoint = self.builder.checkpoint(); // 左辺の手前に印
self.term();
loop {
self.skip_ws();
if self.current() == Some(ExprKind::Plus) {
// 印より後に積んだ左辺を、後から BinExpr で包む
self.builder.start_node_at(checkpoint, ExprKind::BinExpr.into());
self.bump(); // '+'
self.term(); // 右辺
self.builder.finish_node();
} else {
break;
}
}
}
// term() も同じ形で、'*' のときに BinExpr で包む(* は + より内側に入れ子になる)
}
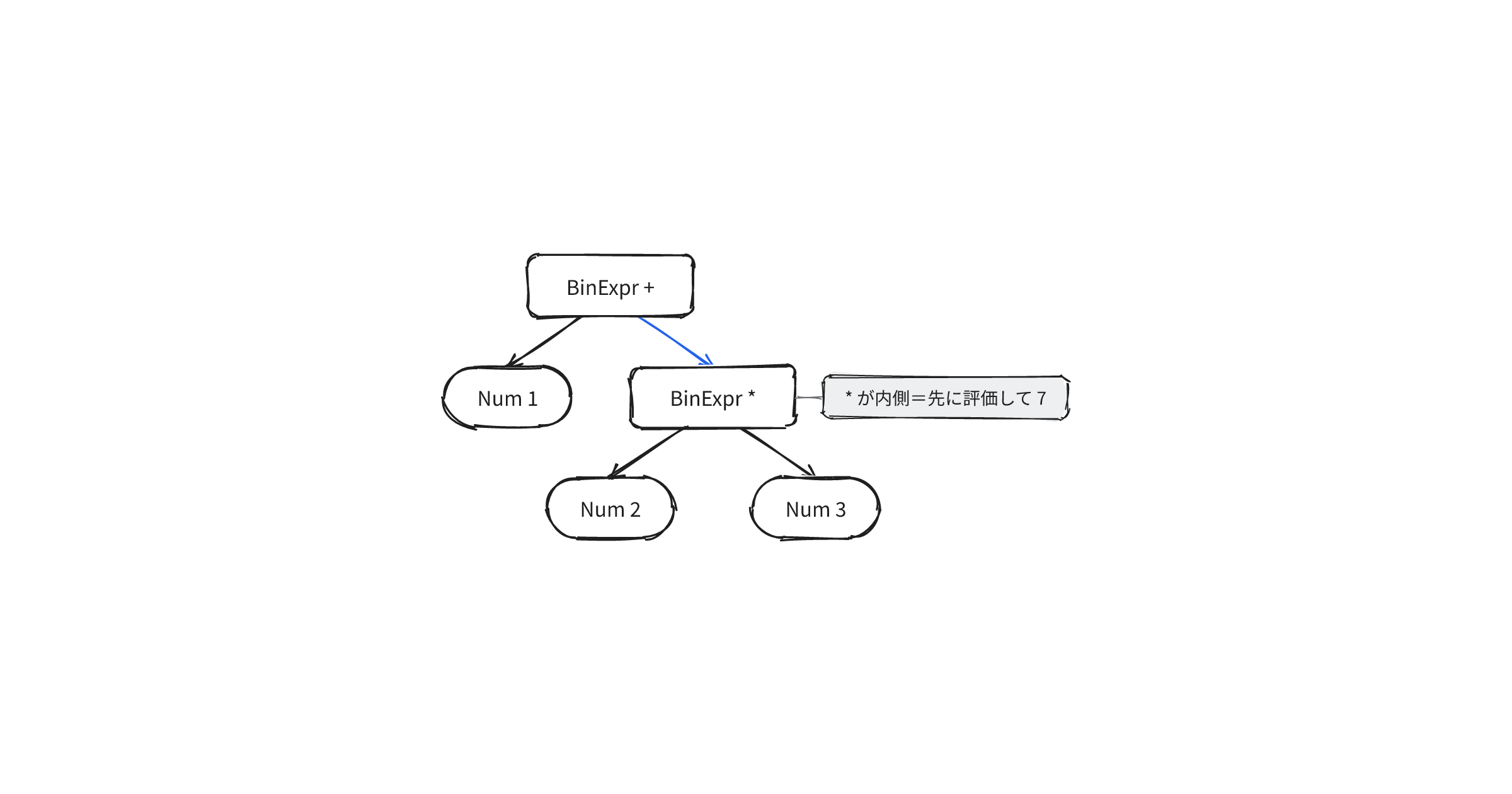
*を+より内側で包むので、優先順位が木の入れ子として表れる。1 + 2 * 3を解析すると、加算の右辺に乗算が入れ子になる。空白はWsトークンとして木に残り、ここでもロスレスを保つ。
Root
BinExpr
Num "1"
Ws " "
Plus "+"
BinExpr
Ws " "
Num "2"
Ws " "
Star "*"
Ws " "
Num "3"
この木をたどって評価すると、乗算が先に畳まれて1 + (2 * 3)となり、7を返す。構造が優先順位を保つので、評価は木の形へ素直に従う。
エラーノードで壊れた入力を受ける
rowanには組み込みのエラー型がない。代わりに、自分の種別へErrorを1つ足し、期待外の入力をそのノードに収めて先へ進む。木は最後まで組み切れ、原文も保たれる。
fn factor(&mut self) {
self.skip_ws();
match self.current() {
Some(ExprKind::Num) => self.bump(),
_ => {
// 期待外。Error ノードに包んで 1 トークン進め、木は壊さない。
self.builder.start_node(ExprKind::Error.into());
if self.pos < self.tokens.len() {
self.bump();
}
self.builder.finish_node();
}
}
}
1 + @のように壊れた入力を与えても、@がErrorノードに入るだけで、木は組み上がる。実際に組み上がる木は次のとおりで、@がErrorノードに収まっている。
Root
BinExpr
Num "1"
Ws " "
Plus "+"
Ws " "
Error
Error "@"
Errorノードの数を数えれば1つ、原文の往復一致は保たれ、評価は壊れていることを表す結果を返す。入力途中の不完全なコードを扱うエディタにとって、壊れた入力から木を組み切れることは重要な前提になる。実際の構文ハイライトや補完は言語サーバの設計しだいだが、壊れない木がその土台を支える。
error nodes: 1
eval(1 + @) = None
broken lossless: ok
位置を保存して再解析後に引き当てる
SyntaxNodeは木に紐づくので、原文を編集して木を作り直すと、古いノードは新しい木では使えない。SyntaxNodePtrは、ノードの種別と木の中での出現順の位置だけを軽く保存する。原文を再解析した木に対して、保存しておいたポインタから対応するノードを引き当て直せる。
use rowan::ast::SyntaxNodePtr;
use crate::cst::{self, ProseLang, SyntaxKind};
pub fn ptr_roundtrip(source: &str) -> bool {
let first_tree = cst::parse(source);
let heading = first_tree
.descendants()
.find(|node| node.kind() == SyntaxKind::Heading)
.expect("見出しがある前提");
// 位置だけを保存する。木そのものは持たない。
let pointer: SyntaxNodePtr<ProseLang> = SyntaxNodePtr::new(&heading);
// 同じ原文を解析し直した別の木へ引き当てる。
let second_tree = cst::parse(source);
let resolved = pointer.to_node(&second_tree);
resolved.kind() == heading.kind() && resolved.text_range() == heading.text_range()
}
同じ原文を解析し直した木なら、引き当てたノードは元と同じ種別を持ち、バイト範囲も元に一致する。原文が変わると範囲は動くが、対応するノードへたどり着ける。診断結果やしおりを、再解析をまたいで保ちたいときに使う。インクリメンタルな再解析では、変わっていない部分木をgreenの共有のまま再利用し、変わった箇所だけ作り直すことで、こうしたポインタの引き当てを安く保つ。
どんなときにrowanが効くか
ここまでの性質を、用途に対応づける。判断軸は、原文の体裁を保つか、位置を正確に扱うか、木の一部を再利用するか。
| 用途 | 効く性質 | 具体的な使い方 |
|---|---|---|
| フォーマッタとcodemod | ロスレス、原文の体裁保持 | 触らない箇所を1バイトも動かさず対象ノードだけ書き換える |
| エディタとLSP | 位置、差分再解析、エラー回復 | カーソル位置から構文を引き、入力途中でもハイライトを出す |
| linterと文章解析 | 位置写像、型付きビュー | 指摘を原文のバイト範囲へ戻し、修正候補を安全に当てる |
フォーマッタとcodemodで体裁を保つ
整形や一括変換では、変えたい箇所以外を原文のまま残せることが品質に直結する。ロスレス構文木なら、対象のノードだけを差し替え、周囲の空白やコメントをTriviaとして保ったまま再出力できる。識別子の一括リネームのように、構造を理解したうえで一部だけ書き換える処理に向く。
エディタとLSPで差分を扱う
エディタは、編集のたびに全体を解析し直すと重い。greenの構造共有とredの遅延生成により、変わっていない部分木を再利用し、変わった箇所だけを作り直せる。SyntaxNodePtrで位置を保てば、再解析をまたいで診断やカーソル対象を追える。エラー回復が前提なので、入力途中の壊れたコードでも構文を引き続けられる。
linterで指摘を原文へ戻す
Markdownの文章を解析するlinterは、装飾やコードを除いた散文だけを、原文上の正確な位置とともに取り出す必要がある。descendants_with_tokens()でテキストのトークンを位置つきに集めれば、指摘を原文のバイト範囲へ正確に戻せる。修正候補もバイト範囲で表せるので、構造を跨いで原文を壊さずに当てられる。この記事のprose_spansは、その最小の形にあたる。
設計の要点と使いどころ
rowanは、原文を1バイトも捨てない構文木を、不変なgreenの木と位置つきのredの参照ビューに分けて表現する。種別を#[repr(u16)]の列挙で定義し、Languageトレイトで載せれば、任意の文法に対して組み立てから走査、意味づけまでが一貫して扱える。
| 段階 | 使う道具 |
|---|---|
| 組み立て | GreenNodeBuilderの開閉と、隙間をTriviaで拾うロスレス化 |
| 走査と参照 | descendantsなどの走査と、text_rangeによる原文への写像 |
| 意味づけ | castによる型付きビュー |
| 一段深い道具 | checkpoint、エラーノード、SyntaxNodePtr |
原文の体裁と位置を保ったまま構造を引けることは、フォーマッタやエディタ、linter、コード変換のように原文へ戻る道具で土台になる。落とさないことは、こうした道具を作るときの確かな足場になる。